Task 2 - Evaluating the supporting data sets
Goal
The goal of Task 2 is to evaluate the quality of the data from which
earthquake parameters are derived (supporting data sets). For this purpose
it is necessary to define a tool (scale), simple enough for classifying
a large amount of supporting data sets. This tool will then be used for
sorting out multiple determinations and providing a preliminary file of
earthquakes.
The following considerations mainly apply to data of earthquakes before
1900 and to macroseismic data after 1900, though they can be adapted also
to instrumental data.
2a - Methodology
The supporting data sets
How "good" are the supporting data sets of our PEC? Where do they come
from ?
It seems reasonable to assume that each catalogue entry (set of earthquake
parameters) was compiled on the basis of a supporting data set (historical,
instrumental, mixed, etc.), according to some procedures. Therefore, the
quality of parameters depends on both determination procedures and supporting
data sets.
Procedures used to determine parameters are sometimes described in
the "introductions" to the catalogues; their analysis and improvement belong
to Task 5.
Supporting data sets show a great variety of type. They range from
a few lines, compiled by someone with the aim of summarising the earthquake
knowledge, to papers or monographs reporting comprehensive investigation
on specific earthquakes.
Catalogues mentioning their supporting data sets normally put numerical
or alphanumerical codes in the column "reference" and supply the key to
the code in a comprehensive bibliographical list. In many PEC each entry
has a single bibliographical reference; in other cases each entry may have
multiple references. In a few cases references are not explicitly linked
with earthquakes, but they are simply quoted in the introduction to the
catalogue altogether. The situation of input PEC with respect to references
is given in Tab. 2.1.
References belong to the following typologies (see some examples in the box Examples of references (supporting data sets) from the BEECD Working File.):
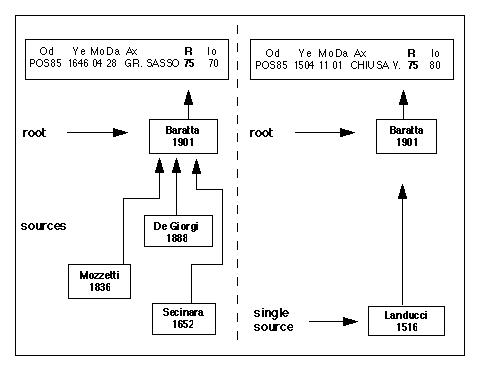
Sources, references and roots
The historical investigation of an earthquake is usually performed
dealing with a number of sources: the investigator summarises the
information gathered from the sources in a report where he provides
some overview of the investigation and the main points on the effect distribution.
The sources are then quoted at the end of the study as references.
Now, it seems reasonable to assume that, for each earthquake, the data
set used by the catalogue compiler for determining the parameters is the
whole output of the investigation and not the single sources, even if this
output is not formally reported. Also in the case of one source only, the
compiler must interpret the information provided by the source in terms
useful for seismological scopes before using it.
The output of the investigation, prepared in the view of a seismological
use, can assume the form of a report, a study, a map of intensity data
points, etc. and will be called hereafter the root of
the parameters.
The sketch below explains these concepts.
A root scale
The problem of qualifying the supporting data sets, or roots, was discussed
in the frame of European workshops, such as the meetings of ESC Historical
Earthquake Data and Macroseismology Working Groups in Liblice (1990), Milano
(December 1993), Athens (September 1994) and Police (November 1995). Though
there is an agreement on the fact that the average quality of supporting
data sets is far from being satisfactory (e.g.: Stucchi et al., 1991a;
Stucchi, 1993; Vogt, 1994a), there is not yet a commonly accepted method
to improve them. For instance, Alexandre (1990; 1994) suggests to disregard
parametric catalogues and to re-compile earthquake catalogues starting
from a thorough research based on the rules of historical criticism only;
others (e.g.: Guidoboni and Stucchi, 1993; Ambraseys et al., 1994; Albini
et al., 1996a) suggest that results achieved by previous researchers should
be taken into account by means of a careful handling and of a critical
interpretation of data sets supporting their seismological interpretation.
Let's examine today situation as it comes out from the survey of current
PEC.
In many cases supporting data sets come from the layers of a sedimentation
process through which the original information (primary earthquake records)
was interpreted and manipulated, from the time the earthquake took place
to today (Marmo, 1989; Alexandre, 1991). Obviously, the quality of such
data sets depends on how much the adopted layer of interpretation is close
in time to the earthquake, how reliable are the sources which are supporting
that layer and how good was the historical interpretation. For instance,
the catalogues by Shebalin et al. (1974), Postpischl (1985a), Leydecker
(1986), Herak (1995) mostly rely on other parametric earthquake catalogues,
while the catalogues by Ribaric (1982), Zsíros et al. (1988), Papazachos
and Papazachou (1989) and Houtgast (1992) rely on earthquake compilations.
Furthermore, data sets are presented according to different levels of formalisation:
from very detailed monographs where all aspects and problems have been
taken into account and possibly solved (such as Rodríguez de la
Torre, 1984; Wechsler, 1987; Gutdeutsch et al., 1987; Figliuolo, 1988;
Ambraseys and Finkel, 1989; Stucchi et al., 1991b; Ambraseys and Karcz,
1992; Grünthal, 1992; Hammerl, 1992; Moroni and Stucchi, 1993; Lambert
et al., 1994; Olivera et al., 1994a), to synthetic studies, such as Postpischl
(1985b), Ambraseys and Finkel (1995), Vogt (1994b), Alexandre (1994), Castelli
(1993), to collections of earthquake records put together in a folder,
stored in some institutions' cupboards.
In many other cases supporting data comes from the top layers of the
sedimentation process; that is, supporting data is another parametric catalogue,
from which compilers simply imported the parameters. This is mostly the
case of the European catalogue (Van Gils and Leydecker, 1991), the catalogues
for Italy (Postpischl, 1985a), for Albania (Sulstarova and Kociu, 1975a),
for Croatia (Herak, 1995). In their turn, such parameters may come from
unreliable data sets: they can have been determined according to other
procedures and may have been just copied or even been altered to some extent
without notice.
A very complicated scale would therefore be needed to classify every
aspect of supporting data sets which have revealed to be so different from
each other. On the other hand, the large number of PEC entries to be evaluated
and the broad scope of the classification call for a robust, easy to use,
tool. Therefore, one must be ready to accept that intermediate cases will
not easily fit in this classification and might escape a clear assessment.
Two main aspects will be considered in developing a classification
of supporting data sets: type and quality. Type means the
degree of seismological formalisation according to which the data set is
organised. Quality has to do with the quality of the sources, in its turn.
Root type
Earthquake studies are papers, reports, compilations where the author
put together the information coming from earthquake records and came to
some conclusions with respect to earthquake time, most affected area, effects
distribution, etc.
Studies may range from papers or monographs devoted to individual earthquakes,
such as Alexandre et Vogt (1994), Glavcheva and Radu (1994a), Vogt and
Grünthal (1994), Grünthal and Meier (1995), to compilations devoting
a few lines to each event, such as Papazachos and Papazachou (1989), Ambraseys
and Jackson (1990) (in these cases the portion of earthquake compilation
which is dedicated to a single event is one study). Top studies are those
performed according to historical seismology methods: they usually present
conclusions in a report explaining how earthquake records were assembled
with respect to both historical and seismological criticism and which are
the unsolved problems, if any. Obviously, we assume that earthquake studies
are better roots than PEC.
With respect to type, roots have been divided into five classes, in the following order of preference which corresponds to a decreasing level of formalisation:
Type 2: earthquake studies
Earthquake studies as described above, but where earthquake effects
are not assessed in terms of intensity at each place belong to this type.
For instance, this is the case of the 1640 earthquake in Northern Europe
(Vogt, 1994c). Most seismological compilations (Davison, 1899; Baratta,
1901; Schorn, 1902; Rethly, 1952, etc.) and early studies can be inserted
in this type.
Modern studies giving only symbols for "strong", "damaging" and so
on are also associated to type 2, considering that they need some interpretation
to be upgraded to type 1 (see for instance, Albini et al., 1994b).
Type 3: earthquake material
In many cases, compilers determined parameters from material at a stage
of formalisation earlier than a study. Records pertaining to an
earthquake were assembled and put in a folder, the author had an idea of
how the effects distribution looked like, the research was still in progress
but he had no time nor intention to reach or write down any conclusions.
This situation is obviously one step back with respect to "literature"
or "earthquake study" (type 2). Perhaps what is lacking is only that the
conclusions are not written and, therefore, such situations can be in principle
easily upgraded to type 2 and even to type 1.
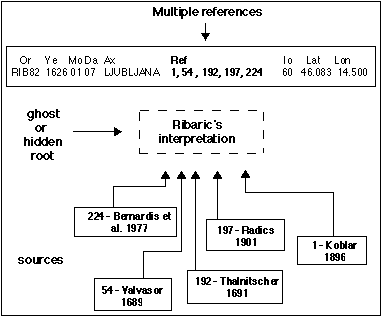
Multiple references for which no root (main reference) can be
assessed belong in principle to this type. They will normally be considered
of type 3; only in the case that all references are PEC, the type will
be 4.
Type 4: set of parameters exported from other PEC
As the preliminary survey presented in Tab.
2.1 has shown, parametric earthquake catalogues are frequently used
as roots for BEECD input PEC entries. Parameters can have been:
Type 5: unknown
Some PEC do not supply references in connection with each earthquake,
or they just supply a general list of references in the introduction to
or at the end of the catalogue, without any possibilities of referring
them to each earthquake. This means that there is no way to find out the
root, without exceeding in interpreting the author's indications. Such
roots will preliminary be given the worst rank, but it is possible that
further investigation will bring them up in the ranking.
Root quality
The quality of a root depends on the quality of sources used and historical
reconstruction. While the latter cannot be assessed unless doing it again,
the quality of the sources quoted by the roots of type 1 to 4 can
be assessed more easily. Irrespectively of its type, a root can rely on:
Quality B: primary historical sources and compilations (secondary
sources)
Most roots use information derived by sources other than primary historical
ones, such as:
Quality C: compilations (secondary sources) only
A short description of this kind of sources was given above. The most
common case of a quality C root is that of most seismological compilations.
They do represent the most widespread kind of root used by input PEC, because
they supply an "in nuce" study for each earthquake; though they consist
of a minimum amount of information only, the compilers found them very
suitable for determining the earthquake parameters.
Root class
According to the methodology above described, the root class
is assigned by the combination of type and quality: 1A, 1B, 1C and so on.
App.
A1 to A11 present 11 examples of root class assessment (all root classes
except 4A, never assessed, and 5) concerning the same amount of entries
from different PEC and on what reasons they were attributed to each root
class.
It has to be stressed that the root class is assigned to the root with
respect to each earthquake, and not to the reference in general. This means
that the same reference, such as Sulstarova and Kociu (1975b), can be classified
as type 1 for the 1865, October 10, earthquake for which it supplies intensity
data points and as type 2 for the 1858, September 20 earthquake, for which
it gives only an effects description.
More often it will be possible to assess for the same reference a different
quality, such as A and C. The most typical example is the case of a late
19th century compilation, which can summarise the information on a 16th
century earthquake, but supply original, primary data for a coeval event
(e.g.: Volger's compilation (1857) on Swiss earthquakes from the year 562
to about 1830 will be of quality C, while it will be of quality A for the
years 1830-1857).
Root levels
Root classes can be put in a hierarchical scale by evaluating how far
they are one from another; the best way is to estimate how much work has
to be done to upgrade a root to an upper class. A closer look to the root
classes suggests three levels (see table below):
|
|
|||||
|
type
|
1 |
studies 2 |
material 3 |
4 |
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(may become good with some effort) |
|
|
|
|
|
|
|
|
|
|
|
|
|
(needs substantial investigation) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2b - Results
Application of the root scale
The root scale was applied to all input PEC of the BEECD WF, which
contains 13.220 entries. The classification was performed by partners and
other researchers who collaborated with the project: in all, approximately
10 people. The classification started after a workshop (July 1995, Milano)
in the framework of which first methodological aspects of the root scale
were discussed and then some cases from different PEC were chosen as test
samples.
A first version of the root scale was prepared and tested within the
first year of the project. The tests done by partners and researchers evidenced
some weak points of the scale and asked for some calibration. As a consequence,
both methodology and number of root classes were adjusted, taking into
account the suggestions coming from the partners (Musson, 1996; Albini
et al., 1996b; Albini and Stucchi, 1997; Stucchi and Camassi, 1997).
The summary results of the application of the root scale to the input
PEC and some comments are presented in the App. B1 to B20.
Here follow some case histories.
"Default" classification
Some PEC revealed some peculiarities with respect to supporting data
sets; therefore, the application of the root scale was in these cases guided
by general considerations, not exactly foreseen by the methodology described
in Part 2a.
All VGL91 entries (649) do not carry any roots and they should have
been classified 5. It was preferred to classify them 4C by default, as
the authors explicitly mention in the introduction that this PEC was compiled
by merging "national" files supplied by European institutions.
The input PEC for the Iberian peninsula, MEM83, quotes its roots in
a general reference list, without any explicit links between each root
and each entry; therefore it should have been classified as in the previous
case. However, its supporting data consists of a large amount of seismological
compilations and earthquake studies which have been considered of a uniform
type and quality; therefore, a root class 3C was assigned by default to
all its entries (1.149).
LAA96 is in conditions very similar to MEM83, that is no explicit links
between roots and entries. Since the supporting data sets appear to be
of a better quality, all its 417 entries were given a root of class 3B,
with the exception of 41 entries for which this PEC supplies the list of
references, which were assessed as of class 3A.
The set of "Additional Determinations" (AD.DET), made by 673 entries
coming from three files (ADBUL from Bulgaria, 197 entries, ADLEN from Austria,
116 entries, and ADVCA, 360 entries, from Belgium), was assigned to root
class 5.
Roots availability
When the roots were available to the researchers performing the classification,
the application of the root scale was done on a steady and reliable basis.
Sometimes they were not, and this was not an unfrequent case. However,
it was out of the scope and possibilities of the project to retrieve all
the not available roots, which would have meant, for most cases, to perform
again the investigation from the beginning. Whenever roots where not available
on the operators' desks, the choice was to assess the more conservative
level both for type and quality.
Same item, different root class
The application of the scale was based on the analysis of the root
supporting a specific entry. In many cases the same item acts as root for
many entries; therefore it was necessary to give the root class to the
part or section of the item chosen as the root for each entry. This means
that it is a consequence of a correct root classification to assess different
root classes to the same root with respect to different entries. Some case
histories are described in detail in App. B.
Problems in applying the root scale
a) Same earthquake, same root, different Rc
The study by Rethly (1952) is the root for the same earthquake in different
PEC in a few cases. When assessing the root quality, the researcher who
classified ZSA88 considered more important the fact that Rethly had in
his hands a set of primary sources, and assessed for this root class 2A
or 2B. On the other hand, the researcher who classified LAB95 took into
consideration the fact that Rethly is a seismological compilation, re-elaborating
both primary sources and compilations and gave to such root class 2B or
2C. However, this happened only for a few
roots and the difference did not affect the following step (choice among
multiple determinations).
b) Same earthquake, similar roots, different Rc
In other cases, supporting data sets (roots) for the same earthquake
are quite similar and the differences in classification depend on the slightly
different points of view of the researchers who did the assessment. This
is mostly the case of some seismological compilations, such as Sieberg
(1940b) or Rethly (1952), Sieberg (1940b) or Montandon (1953), etc., dealing
with the same earthquake. Once again, the different Rc assessment did not
affect the following step.
"Hidden" roots
Some difficulties were met in identifying the main root to be classified
in case of multiple references; as explained in Part 2a - Methodology,
it was not always possible to find out the root and a "ghost" or
"hidden" root (HID, type 3) was assessed to overcome this situation.
Inside the BEECD Working File the hidden roots are about 46% out of
the roots of type 3 (1.169 HID roots out of 2.496 roots of type 3). There
are only 71 HID roots classified as 4C, all of them in SHA74. Though it
was not possible to identify the main root, all references were parametric
earthquake catalogues, making the type 4 prevail on type 3.
The classification of hidden roots resulted different only with respect
to quality, which was assessed mainly on the basis of the quality most
represented inside the supporting data set. HID roots are equally divided
between quality B (50%) and quality C (44%).
Fake quakes
This problem does not concern the roots of the input PEC, but rather
the studies, analysed in the frame of Task 3, which prove that an earthquake
listed in the input PEC is fake, because some original information was
later distorted: in this case the study will not give datapoints (therefore,
type 2). As for the quality, in most cases the source of distortion will
be found far in time from the event; consequently, no primary source should
come in the game (therefore, quality C).
However, these studies do use primary sources close to the distortion,
which actually represents the "event" which gave birth to the entry; moreover,
in some cases the sentence of "fake" is issued after checking some primary
sources contemporary to the presumed quake, which turn out silent with
respect it. Therefore, considering that such studies supply an effective
contribution which in most cases cannot be upgraded, they were assigned
quality B in most cases.
Conclusions
Type and quality were uniformly assessed by different researchers involved
in this particular task, though the agreement on the meaning and application
of the root scale were reached only after workshops (July 1995, Milano;
November 1995, Milano) and bilateral meetings and discussions among partners
and operators.
The supporting data sets which gave origin to each PEC are reflected
by some "clusters" of classes in some of them (e.g.: 5 classes for SUK75,
4 classes for MUS94 and LEY86, 3 classes for SHA74 and HER95, 2 classes
for COM82).
When 7 or more classes are present, this could be seen as a consequence
of a larger supporting data set available for this PEC and may be as well
of a better knowledge of its roots by the researcher who did the classification
(e.g.: 7 classes for GRU88, LAB95, PAP89; 8 classes for POS85, RIB82 and
ZSA88; 10 classes for KSH82).
In all, the application of the root scale was successful from a general
point of view and within the scopes of this task of the project. The root
scale turned out to be a useful tool, though not all the 13 classes, obtained
by combining type and the quality, are significantly present in the WF.
Root class and root level distribution
The distribution of root classes within each PEC for the time-window
1400-1899 (total figures and percentages on each input PEC) is given in
Tab.
2.3, Fig. 2.1 and Fig.
2.2. As it can be seen, the distribution varies substantially from
one PEC to another. With respect to quality, the best ranked input PEC
are MUS94, LAB95 and ZSA88.
The distribution pattern is not uniform in time. Some particularities
in distribution appear when looking at different time-windows. Root class
1A (1%) is represented in more than one PEC only between 1850 and 1899.
With the exception of one root of POS85 for the 18th century, between 1400
and 1849 all roots of class 1A belong to only one, that is MUS94. Between
1500-1599 the three root classes of type 2 are the 42%, by far the most
important cluster inside the general time-window (1400-1899).
The time-window which shows the largest distribution of root among
classes is 1850-1899, while the period when class 4C, the most represented
one, is the most significant as well is between 1700 and 1799 (48,5%);
in the same time-window class 2C is the 17% only. As an example, Fig.
2.3 and Fig. 2.4 show the same analysis of Fig. 2.1 and
Fig. 2.2 in the time-window 1500-1599: in this time-window
HOU92 shows a better performance.
Obviously, the overall situation improves if we consider only large
earthquakes (Ix/Io _ 7/8 or M _ 5.2; Tab. 2.4, Fig. 2.5 and 2.6).
The percentages of the best root classes are higher than in the whole BEECD
WF; GRU88 shows a quality peak. Here, again, the distribution pattern is
not uniform in time: Fig. 2.7 and Fig. 2.8 shows the same analysis
of Fig. 2.5 and Fig. 2.6 over the time-window 1500-1599.
Looking at the WF 1400-1899 as a whole (Tab.
2.5, Fig. 2.9 and
Fig. 2.10; percentages on the WF figures),
the most represented class is 4C (39%), followed by class 2C (23%). The
input PEC that mainly contributes to this uneven situation is POS85, which
contains the 63% of roots located in class 4C and the 74% of roots assessed
in class 2C. Root class 3C constitutes the third important root class (13%),
followed by root class 2B (9%).
Finally, Fig. 2.11 , Fig. 2.12 and 2.13 give an idea of the distribution
of root type, quality and level - respectively - in the time-window 1400-1899.
The qualified BEECD Working File
The final goal of Tasks 1 & 2 was to compile a comprehensive
list of earthquakes, to find out the best supporting data set (root) available
for each of them and to establish priorities for the investigation.
For this purpose, multiple determinations (MD) of the same event
were sorted out selecting one of each family (same Fn) by means
of the parameter Rc. That is, for each family of MD the entry
carrying the best Rc was selected and given the code F (first)
to the parameter "BEECD preference code" (P, first column). In case
of same Rc among two or more entries, the entry belonging to the
oldest PEC was adopted as F.
Obviously, single determinations (SD) were all given F
by default.
As a general rule, DD entries were never adopted as F;
entries provided by the files defined as "source of additional determinations"
(AD.DET) were considered separately.
A portion of the qualified WF 1400-1899 is given in App. C.
Examples of references (supporting data
sets)
from the BEECD Working File.
Or Ye Mo Da Ho Mi Ax Ref RC Om Ix Io Lat Lon Mm LEY86 1593 02 06 NOERDLINGEN/RIES S40 0 70 48.833 10.500 0
Historical earthquake investigation
Or Ye Mo Da Ho Mi Ax Ref RC Om Ix Io Lat Lon Mm ZSA88 1590 09 15 AUSTRIA 67 90 48.140 16.120 0
Seismological bulletin
Or Ye Mo Da Ho Mi Ax Ref RC Om Ix Io Lat Lon Mm POS85 1898 03 04 21 05 CALESTANO 36 0 70 44.633 10.167 0
Parametric earthquake catalogue
Or Ye Mo Da Ho Mi Ax Ref RC Om Ix Io Lat Lon Mm ZSA88 1830 08 02 11 BRESTANICA 70 0 70 46.000 15.500 50
0080 02 08 1830 10 00 00 46.000 15.500 c 7.00 0.0:000 00.0 0.00 0.00 0.00 00.000 181 1,131
LJU Brestanica
dolina Save, (Val)
An example of how an individual reference
was
chosen as the main one (the root)
among multiple references
Or Ye Mo Da Ho Mi Ax Ref1 Ref2 RC Om Ix Io Lat Lon PAP89 1780 10 HIERAPETRA 72 129 100 34.900 25.800
This entry of the catalogue by Papapazachos
and Papazachou (1989) is supported by the data contained in two texts of
seismological literature.
Code "72" points to an earthquake compilation
by Mallet R., 1854. Third Report on the facts of Earthquakes Phenomena,
Catalogue of recorded Earthquakes from 1606 B.C. to A.D. 1850. Report of
the 22nd Meeting of the British Association for the Advancement of Science,
pp. 1-176, London, who supplies on this earthquake the following information:
| Anno Domini
|
Locality | Direction, duration and number of shocks | Meteorological and other phenomena | Authority |
| 1780 Oct.
Island
Probably at the beginning of this month |
Island
of Candia |
A very
violent
earthquake, preceded by others for some time |
The castle
of
Eropeter with its garrison of 300 Turks was swallowed up Thirteen small villages and their inhabitants disappeared in like manner |
Merc. de
France
of 11 Nov., p. 56, quoting "la rubrique" of Leghorn of the 15th Oct., which quotes letters from Trieste |
Code "129" points to Sieberg A., 1932b. Untersuchungen über Erdbeben und Bruchschollenbau im Östlichen Mittelmeergebiet, Jena, who supplies on this earthquake the following information: