Esperimento di localizzazione accurata nell'area dell'Umbria-Marche
P. Augliera, M. Cattaneo e D. Spallarossa
1. Determinazione del modello di propagazione.
1.1 Selezione dei dati.
Per la determinazione del modello di propagazione ottimale per la localizzazione degli eventi del catalogo, l'approccio seguito è stato quello denominato Joint Hypocenter Determination (JHD): data una serie di tempi di arrivo, misurati ad una rete di stazioni sismiche, per una serie di terremoti, si cerca di calcolare per inversione simultanea sia la posizione ottimale degli ipocentri che le modifiche da apportare al modello di propagazione scelto a priori.
Senza entrare nel dettaglio, e nelle problematiche, del metodo, bisogna rimarcare che questo problema inverso è fortemente non lineare. In questi casi è vieppiù necessario iniziare la procedura con parametri molto ragionevoli, in modo da poter utilizzare un approccio di tipo perturbativo. In altre parole, occorre disporre di un insieme di eventi con una buona localizzazione a priori, e di un buon modello di propagazione iniziale.
Nel nostro caso, ciò ha comportato una selezione molto rigorosa dei dati in ingresso: come già specificato, i tempi di arrivo riportati nel data-set sono talvolta affetti da errori piuttosto vistosi. Inoltre la copertura degli eventi (ossia il numero di stazioni che hanno registrato le varie fasi, e la loro distribuzione geografica intorno all'epicentro) risulta molto disomogenea. Si è quindi effettuata una prima selezione, basata sui seguenti criteri:
- non meno di 10 fasi registrate
- non più di 180 gradi di gap (settore azimutale intorno all'epicentro non coperto da stazioni)
- non più di 1.0 micro s di rms (root mean square dei residui)
- non più di 10 km di erh ed erz (errori statistici stimati di localizzazione).
Ciò ha comportato una riduzione del data set, dagli iniziali 10104 eventi, a 1067 eventi. Chiameremo il risultato di questa estrazione data set 1. Una ulteriore selezione ha adottato criteri ancora più selettivi: gap < 150 gradi, erh < 5km, rms < 0.7s. Ciò ha ridotto il numero di eventi selezionati a 497 (data set 2).
Le localizzazioni preliminari dei due data sets sono rappresentate in Fig. 1. Si può osservare che la distribuzione areale, concentrata principalmente lungo lo spartiacque appenninico, non viene sostanzialmente modificata dalla selezione più rigida, garantendo quindi la significatività del confronto.
1.2 Scelta del modello a priori.
Data l'estensione dell'area in esame, si è deciso in questa prima fase di utilizzare un modello unidimensionale con correzione di stazione. Ciò significa che si assume il campo di velocità come dipendente solo dalla profondità; le eventuali eterogeneità riguardanti la parte più superficiale della crosta, in corrispondenza delle stazioni, vengono (parzialmente) modellate da un termine statico di correzione. Questo approccio (Kissling et al, 1994 ) viene comunemente usato anche come primo passo per una tomografia tridimensionale.
Come modello iniziale di velocità, si è adottato quello ottenuto da Cattaneo et al (2000) analizzando i dati della sequenza Umbro-Marchigiana del 1997 registrata dalla rete temporanea GNDT e dalle reti regionali di Marche, Umbria e Abruzzo. Questo modello, pur essendo finalizzato alla localizzazione di eventi strettamente in zona di catena appenninica, può essere considerato un buon punto di partenza anche per l'area (molto più estesa) in esame.
In realtà tale modello era già stato utilizzato anche per la localizazione "a priori" necessaria per effettuare la selezione descritta nel paragrafo precedente.
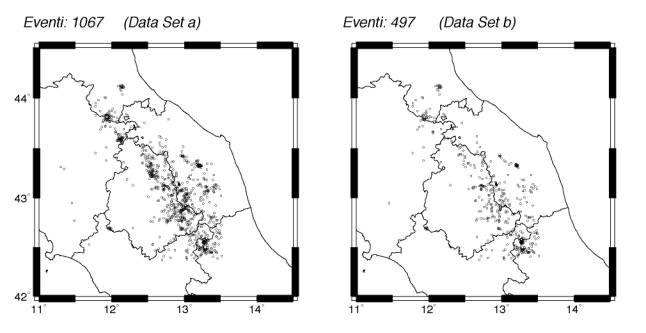
Figura 1 - Localizzazioni preliminari per i microdue data set di prova utilizzati.
1.3 Procedura di inversione.
Per l'inversione contemporanea per localizzazione e modello di velocità, si è utilizzato il codice Simulps12 (Thurber, 1983; Eberhart-Phillips, 1993) con leggere modifiche introdotte dall'U.O. di Genova. Tale codice consente di risolvere il problema non lineare in modo iterativo, separando nel corso delle iterazioni le incognite legate alla localizzazione da quelle legate al modello di propagazione. Ciò consente di smorzare in modo differenziato i vari passi di inversione, e quindi di ottenere soluzioni più stabili ed affidabili.
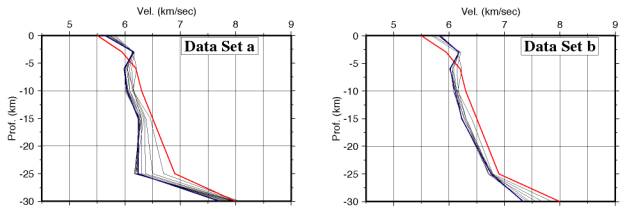
Figura 2 - Modelli di velocità per i due data set di prova.
Sono stati effettuati vari esperimenti di inversione, che differiscono sia per il data-set utilizzato, sia nella scelta di alcuni parameri. In particolare, la procedura di tracciamento di raggi implicita nell'inversione è particolarmente adattata per percorsi di tipo crostale, ma mal si accorda alla propagazione di onde rifratte, come la fase Pn. Risulta quindi necessario dare la massima influenza ai dati forniti dalle stazioni più vicine all'epicentro: ciò viene ottenuto utilizzando in modo appropriato un meccanismo di peso in funzione della distanza.
Similmente, trattando dati provenienti da bollettini e quindi potenzialmente inquinati da errori anche vistosi, si introduce anche un criterio di peso delle singole fasi in funzione del residuo fornito dalla fase stessa: in questo modo si riesce a ridurre, o addirittura ad eliminare, l'effetto degli outliers, ossia dei residui che non rientrano in una statistica di tipo gaussiano e per cui la procedura di minimizzazione tramite minimi quadrati perde significato.
1.4 Modelli ottenuti.
Utilizzando le metodologie descritte nel paragrafo precedente, si sono quindi eseguite diverse inversioni, che hanno portato alla definizione di differenti modelli di propagazione. In Fig. 2 vengono presentati i modelli ottenuti usando i due data-sets: si può osservare che gli strati più superficiali risultano relativamente ben vincolati, e significativamente diversi dal modello iniziale. Per gli strati più profondi, si può notare una certa instabilità: ciò è probabilmente dovuto alla non soddisfacente copertura di raggi, e alla qualità non molto alta dei dati a disposizione, che probabilmente in molti casi non ha consentito di riconoscere come primi arrivi le fasi rifratte nella crosta inferiore.
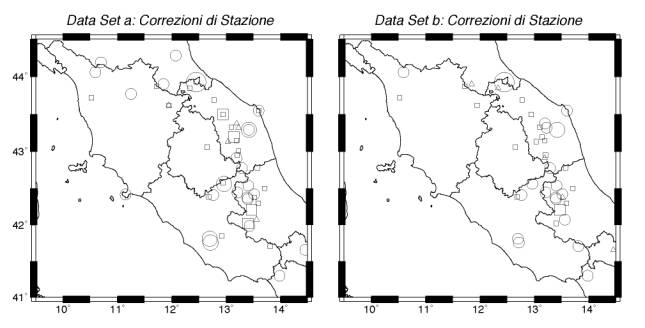
Figura 3 - Correzioni di stazione per i due data set di prova
Come già evidenziato, oltre al modello di velocità la procedura di inversione fornisce dei termini statici di correzione di stazione: anche per tali valori è interessante confrontare i risultati ottenuti dalle micro due inversioni, per verificarne la stabilità. Come si può osservare in Fig. 3, le stazioni caratterizzate da termini di correzione vistosi mantengono una buona stabilità, mentre alcuni termini di minore entità riescono addirittura a mutare di segno tra le due inversioni. In generale, i valori qui ottenuti sono coerenti, ma mediamente inferiori a quelli ottenuti da Cattaneo et al. (2000) dal data set relativo alla sequenza Umbria-Marche 1997. Il risultato non deve sorprendere: in quel caso il modello era stato ottenuto vincolando le localizzazioni tramite una rete temporanea molto densa, e quindi tutto il residuo poteva essere efficacemente mappato nel modello di propagazione. In questo caso molto spesso la localizzazione non è sufficientemente sovradeterminata per ottenere una buona separazione dei parametri di localizzazione da quelli propagativi.
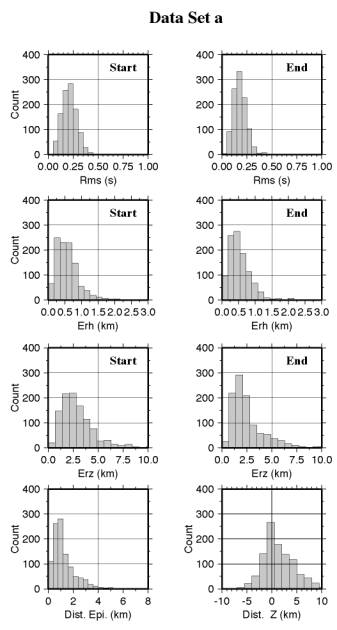
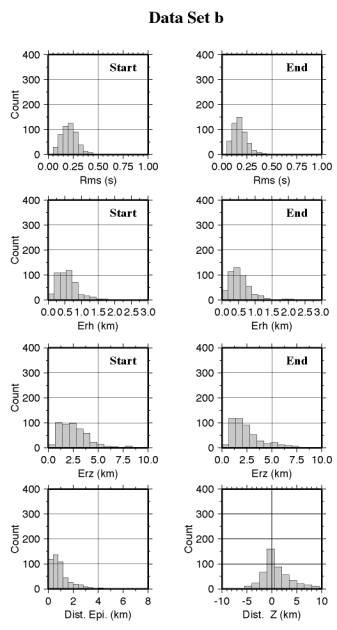
Figura 4 -
Nelle Fig. 4.a e 4.b vengono riportati alcuni parametri statistici di localizzazione, relativi sempre ai due data sets, e riferiti alla prima ed ultima iterazione di inversione. Si può osservare come in entrambi i casi vi sia una riduzione dell'rms medio, più vistosa nel caso a). Anche la stima statistica dell'errore di localizzazione orizzontale (erh) e verticale (erz) presenta una riduzione più vistosa nel primo caso, e similmente la variazione della posizione epicentrale ed ipocentrale. Tutto questo può essere facilmente giustificato: la selezione più rigorosa ha mantenuto soltanto le localizzazioni più stabili, che meno risentono dell'effetto del modello di propagazione. Viceversa, questi dati sono proprio quelli che meglio consentono di invertire per i parametri di propagazione, ed infatti il modello ottenuto dal data set b) sarà quello utilizzato nello sviluppo successivo.
Si è quindi effettuato un tentativo di differenziazione geografica del modello di propagazione: dal data-set più ampio sono stati ottenuti due sottoinsiemi, discriminando gli eventi in base alla loro posizione geografica come determinata dalla localizzazione preliminare. In particolare si sono divisi gli eventi ``tirrenici'', ossia posti a SW dello spartiacque appenninico, da quelli ``adriatici'' (Fig. 5). Ovviamente la distinzione è piuttosto critica, in quanto una notevole percentuale della sismicità è localizzata molto vicino allo spartiacque; inoltre non è stata volutamente effettuata nessuna selezione sulle stazioni registranti, per cui eventi tirrenici sono localizzati anche da stazioni adriatiche e viceversa. Questa scelta è necessaria per evitare di estendere il gap azimutale degli eventi localizzati in catena.
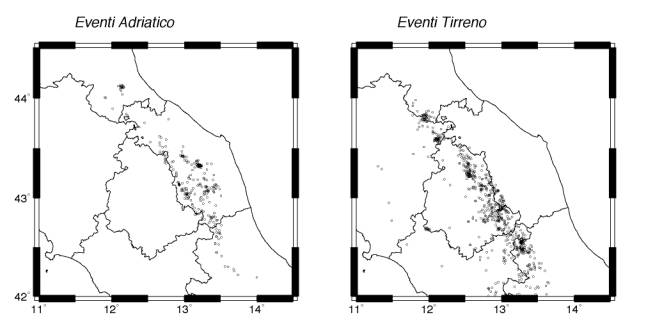
Figura 5 - Localizzazione differenziata geograficamente.
In Fig. 6 vengono riportati i modelli ottenuti con i due data sets: si può osservare come una differenziazione, probabilmente significativa, sia presente. Per verificare il livello di significatività, si sono effettuate prove incrociate, provando a localizzare gli eventi tirrenici col modello adriatico, e viceversa: in entrambi i casi si può osservare un sensibile rialzo del rms.
Comunque, in questa fase si possono considerare questi esperimenti di differenziazione come puramente metodologici: per la localizzazione del data-set completo, ci si è limitati ad utilizzare il modello ottenuto dall'inversione del data set b).
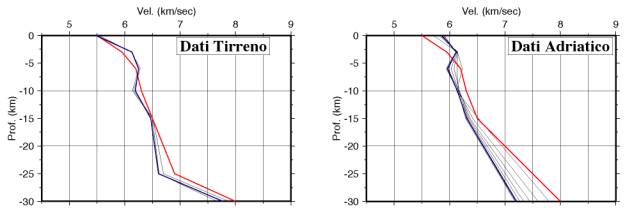
Figura 6 - Modelli di velocità differenziati geograficamente
2 Localizzazione degli eventi
2.1 Perché più localizzazioni
Una volta ottenuto il modello di propagazione, ed i termini correttivi di stazione, si può procedere alla localizzazione del data-set completo delle fasi. A questo scopo, si può utilizzare sempre il codice SimulPS, mantenendo bloccato il modello di localizzazione ed invertendo solo per i parametri focali.
Purtroppo, non sempre la quantità e qualità dei dati è sufficiente per garantire una buona localizzazione: in particolare molto spesso la profondità è molto mal vincolata, data l'alta interdistanza media tra le stazioni. In questo caso, la procedura automatica di localizzazione può ``cadere'' in un minimo relativo, fornendo una soluzione poco attendibile.
Per ridurre le conseguenze di questo problema, oltre all'usuale localizzazione, si sono effettuate altre inversioni vincolando, per ogni evento, la profondità ad un particolare valore. I valori di profondità utilizzati sono stati 0, 5, 10, 15, 20, 25, 30 e 40 km.
Inoltre, a volte i dati a disposizione sono relativi soltanto a stazioni piuttosto lontane dall'epicentro: in questo caso, come già detto la procedura di localizzazione SimulPS non è in grado di gestire percorsi di raggio molto lunghi. Per tali eventi, una localizzazione ``tradizionale'', utilizzando per esempio il codice Hypoellipse, può dare risultati più attendibili. Per tali casi, la profondità è stata bloccata a 10 km, e si è pressoché eliminato il peso in distanza.
In conclusione, per ogni evento si avevano a disposizione 10 localizzazioni: una a profondità libera, 8 a varie profondità e una da modello semplificato. Per scegliere automaticamente, tra queste localizzazioni, quella più attendibile, ossia quella che meglio risponde a criteri non solo di accordo coi dati, ma anche di ragionevolezza, si è adottata una strategia di controllo multiplo di vari parametri.
Infatti l'accordo della localizzazione ottenuta con i dati misurati viene solitamente misurato tramite l'rms dei residui di tempo, ossia degli scarti tra i tempi di percorso effettivamente osservati e quelli calcolati, all'interno del modello adottato, a partire dalla soluzione ottenuta. Purtroppo, questa misura può venire fortemente influenzata dal meccanismo di peso adottato: in caso di basso numero di fasi e/o di fasi non reciprocamente coerenti, può accadere che la procedura di inversione riduca via via il peso a un numero sempre crescente di fasi che mal si accordano alla localizzazione ottenuta, fino a giungere ad un risultato caratterizzato da parametri statistici apparentemente molto buoni, ma che giustificano solo una piccola parte dei dati disponibili.
Ciò è vero soprattutto per il parametro più critico, la profondità focale. Al fine di verificare la stabilità di tale parametro tra la soluzione libera e le soluzioni bloccate, si è analizzata la variazione del'rms tra le soluzioni bloccate: nei casi stabili, i residui tendono a crescere regolarmente intorno al minimo, per cui la curva dei residui in funzione della profondità dovrebbe dare una forma approssimativamente parabolica, con il minimo prossimo al valore di profondità calcolato dalla procedura di inversione. E' quindi sufficiente interpolare i valori di rms con una funzione parabolica, calcolare il minimo di tale interpolazione e verificare la coerenza o meno di tale valore con quello ottenuto dall'inversione. Solo i valori che hanno superato tale test sono stati considerati nella successiva fase di confronto.
2.2 Selezione delle localizzazioni
Come detto, per ogni evento erano disponibili fino a 10 localizzazioni: quella ottenuta dall'inversione (purché superasse il citato controllo di congruenza con le soluzioni contigue), le 8 bloccate e quella a modello semplificato. La discriminazione tra tali soluzioni è avvenuta sulla base di vari criteri micro statistici.
I parametri utilizzati per il confronto tra le varie localizzazioni sono stati:
- numero di fasi effettivamente utilizzate
- rms dei residui
- erh e erz (errori statistici stimati in orizzontale e verticale).
Nei casi più fortunati, i vari criteri sono concordi nel definire la soluzione migliore, ossia quella che definisce contemporaneamente il minimo rms, i minimi erh e erz, e un numero di fasi utilizzate coincidente, o molto prossimo, al numero totale di fasi disponibili: in questo caso la scelta è ovvia. Nella maggioranza dei casi, purtroppo ciò non avviene, ed occorre quindi introdurre dei criteri di discriminazione: nella versione attuale, si è data importanza prioritaria al numero di fasi effettivamente utilizzato, quindi ai parametri statistici (in particolare erh, essendo erz a volte instabile a sua volta) e infine all'rms. In particolare, micro si è evitato di selezionare soluzioni caratterizzate da numero di fasi troppo basso, e quindi intrinsecamente instabili.
Per quantificare i risultati, possiamo dire che, dei 10220 eventi localizzati, solo per 1603 è stata scelta la soluzione libera, con una profondità proveniente dall'inversione (classe A). Per 7228 eventi (classe B), è stata comunque fornita una profondità in base a una oggettiva prevalenza di tale soluzione rispetto alle altre, mentre per 1389 localizzazioni (classe C) si è adottato il valore standard di 10 km, non essendo possibile discriminare tra le varie soluzioni. La distinzione tra classi B e C non è solo formale: mentre per i dati di classe B il valore di profondità non è strettamente predefinito, e quindi dovrebbe contenere una qualche informazione, sia pur non ottimale, per quelli di classe C il parametro profondità viene introdotto in modo assolutamente aprioristico, non avendo quindi nessun contenuto di informazione se non strumentale alla localizzazione. E' ovvio che, per analisi di dettaglio sulla distribuzione in profondità della sismicità, solo gli eventi di classe A possono fornire un'informazione di livello adeguato.
Non deve stupire il numero basso di eventi per cui una determinazione di profondità risulti stabile: fino a relativamente pochi anni fa, la geometria di rete nell'area in esame era troppo rada per garantire una adeguata copertura in distanza, particolarmente per gli eventi più superficiali. E' noto infatti che, per una determinazione stabile della profondità ipocentrale, è necessario disporre di registrazioni poste a distanza confrontabile con la profondità stessa: la disponibilità di arrivi provenienti soltanto da fasi rifratte, e non dirette, rende infatti la profondità non determinabile, dato il trade-off che si viene a creare tra profondità e tempo origine. L'utilizzo di fasi S riduce parzialmente questo problema, ma non riesce ad annullarlo.
Se esaminiamo una statistica della distanza epicentrale della terza stazione più vicina per la totalità degli eventi localizzati (Fig. 7), è facile osservare che solo per un numero molto ridotto di eventi questo dato risulta inferiore o confrontabile a 10 km. Ciò implica che per tutti gli altri eventi la determinazione della profondità, soprattutto qualora questa sia inferiore a 10 km, risulta molto critica.
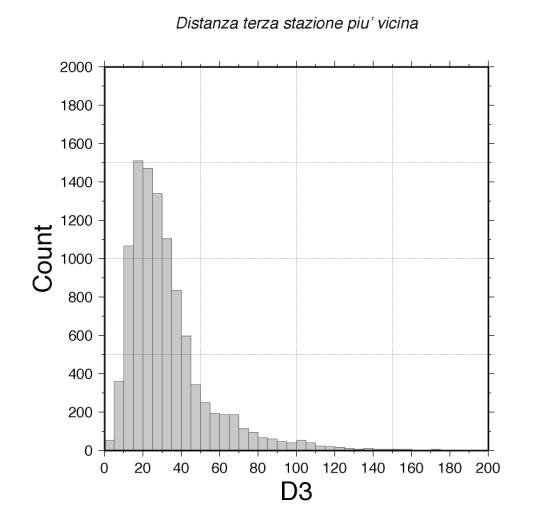
Figura 7 - Istogramma in funzione della distanza epicentrale della terza stazione più vicina
2.3 Localizzazioni finali
Il prodotto finale della procedura sopra descritta è quindi un file contenente la localizzazione ritenuta migliore per ogni evento; la localizzazione comprende tutte le informazioni complementari (errori stimati, gap azimutale, rms, ...) secondo il formato "summary card" del programma hypo71.
Una visualizzazione di tutti gli epicentri così ottenuti (figura 8a) può risultare interessante soprattutto per evidenziare la quantità di informazione contenuta nel data-set, intesa come numero di eventi. Se invece si volesse analizzare più nel dettaglio la distribuzione spaziale della sismicità, risulta senz'altro conveniente utilizzare anche le altre informazioni, ed estrarre solo gli eventi localizzati con la precisione ritenuta necessaria per lo scopo specifico. A titolo di esempio, in figura 8b viene riportato il risultato di un'estrazione degli eventi con erh e erz minore di 5 km, e con almeno 8 fasi utilizzate per la localizzazione. Risulta evidente come il numero di eventi sia in questo modo fortemente ridotto, ma come d'altro lato la distribuzione della sismicità appaia molto meglio definita, eliminando l'effetto "nuvola" legato a localizzazioni instabili.
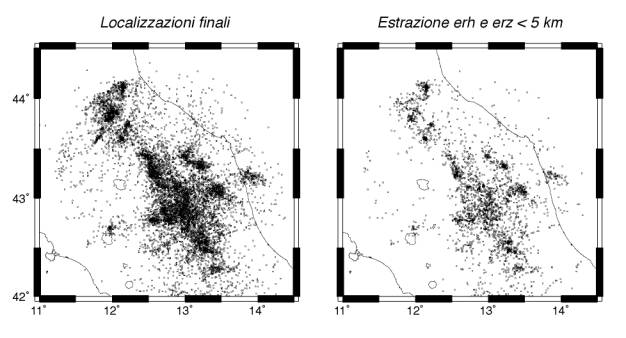
Figura 8 - Distribuzione spaziale delle localizzazioni finali
Bibliografia
Cattaneo M., Augliera P., De Luca G., Gorini A., Govoni A., Marcucci S., Michelini A., Monachesi G., Spallarossa D., Trojani L. and XGUMS, 2000. The 1997 Umbria-Marche (Italy) earthquake sequence: analysis of the data recorded by the local and temporary networks. J. Seismology, in press.
Eberhart-Phillips, D., 1993. micro Local earthquake tomography : earthquake source regions, in Seismic Tomography: Theory and Practice. H.M. Iyer & K. Irahara eds., Chapman and Hall, New York, 613-643.
Kissling, E., Ellsworth, micro W.L., Eberhart-Phillips, D., micro Kradolfer, U., 1994. Initial reference models in local earthquake tomography, J. Geophys. Res. 99, 19635-19646.
Lahr, J.C, 1979. Hypoellipse a computer program for determining local earthquake parameters, magnitude and first motion pattern. U.S. Geol. Surv., Open File Rep., 79-431.
Thurber, C.H., 1993. Local earthquake tomography: velocities and Vp/Vs . Theory, in Seismic Tomography: Theory and Practice. H.M. Iyer & K. Irahara eds., Chapman and Hall, New York, 563-583.