| Home | Partecipanti | Introduzione | Programma |
|
|
|
|
|
|
|
|
Dario Slejko
Osservatorio Geofisico Sperimentale, Trieste
Che cosa ci dicono le attuali stime di pericolosità sismica nazionale e cosa si può fare di più
Le stime finali di pericolosità sismica per il territorio nazionale sono state consegnate recentemente al Dipartimento della Protezione Civile: esse dovrebbero rappresentare la base informatica per la futura classificazione sismica italiana. Questo risultato è stato raggiunto dopo un lavoro pluriennale che ha interessato massicciamente il GNDT e rappresenta la fine di un processo scientifico che ha spaziato dalla preparazione di un catalogo di terremoti, attraverso la definizione del modello sismotettonico nazionale e la caratterizzazione sismica delle zone sismogenetiche (ZS), fino alla stima della pericolosità sismica. Il progetto GNDT può essere considerato una fase dovuta ed intelligente verso la definizione del rischio sismico nazionale. Una fase dovuta perchè allinea l'Italia, con l'applicazione della metodologia di Cornell (1968), alla maggioranza delle nazioni scientificamente avanzate in campo di ingegneria sismica: approcci più sofisticati sono stati applicati, infatti, quasi esclusivamente nell'America settentrionale (vedi McGuire, 1993). Una fase intelligente perchè l'applicazione italiana manifesta una globalità progettuale pressocchè assoluta: non c'è aspetto del metodo di Cornell (1968), infatti, che non sia stato affrontato e, generalmente, risolto in maniera personalizzata. Le caratteristiche del progetto GNDT sono così sintetizzabili:
1) è stato utilizzato un metodo probabilistico consolidato (il metodo di Cornell, 1968, per l'appunto);
2) il risultato conseguito (carta di PGA con periodo di ritorno 475 anni) rappresenta un prodotto convenzionale (per esempio nell'Eurocodice EC8);
3) il progetto presenta una filosofia operativa coerente nell'arco di tutto il progetto stesso.
Nonostante ciò, certi limiti possono essere riscontrati nel progetto
GNDT, limiti venuti via via delineandosi nel corso del progetto e ai quali
si è posto riparo per quanto possibile. Il limite più importante
risiede nella scarsa rappresentatività del parametro PGA nel descrivere
il moto del suolo atteso. Anche se PGA viene ancora considerato il predittore
principe nelle carte di pericolosità, una stima della vibrazione attesa
a fissate frequenze risulta ben più appropriata alla progettazione
antisismica. Collegato a questo aspetto è pure quello delle relazioni
di attenuazione usate. Se per le stime in intensità macrosismica uno
sforzo per utilizzare i dati italiani è stato fatto (relazioni
differenziate per le singole ZS calibrate sulle osservazioni relative al
terremoto ritenuto più significativo per la zona stessa), per quelle
in PGA sono state soltanto confrontate le relazioni italiane ed europee di
letteratura per poi fare una scelta a favore di una di esse. Un altro limite
riguarda le dimensioni limitate di alcune ZS: il contenuto del catalogo dei
terremoti risulta caratterizzato da pochi eventi, al punto tale da rendere
difficile la caratterizzazione della loro sismicità. Un ulteriore
limite consiste nell'importanza marginale rivestita dalle zone background
nella zonazione generale. Ciò deriva dal fatto che si è cercato
di associare alle ZS vere e proprie pressocchè tutta la sismicità
del catalogo. Le ZS background, che dovrebbero raccogliere la sismicità
diffusa non direttamente associabile a specifiche strutture tettoniche, sono
rimaste, così, con pochi terremoti deboli da distribuire su aree piuttosto
vaste. Un ulteriore limite può essere individuato nel fatto che non
sono state condotte in parallelo valutazioni alternative di pericolosità
probabilistica da associare a quella principale qui descritta.
Il superamento di questi limiti comporta un approfondimento delle indagini
finora condotte che può portare ad un significativo miglioramento
delle stime di pericolosità sismica, anche se a livello quantitativo
è lecito ritenere che le differenze non dovrebbero essere notevoli.
Questo miglioramento deriva da un ripensamento della zonazione sismogenetica
che porti all'individuazione di zone quanto più possibile ristrette
dove i terremoti più forti rimangono associati, per quanto possibile,
ad una struttura tettonica definita spazialmente anche dall'analisi dettagliata
della sismicità recente. La condizione di sismicità uniformente
distribuita all'interno della ZS, richiesta dall'approccio di Cornell (1968)
e già considerata nella definizione dell'attuale zonazione, dovrà
essere rigorosamente verificata anche in funzione dei tassi di sismicità
ottenuti dal catalogo dei terremoti e delle evidenze tettoniche e
paleosismologiche. Per caratterizzare meglio la sismicità delle ZS
risulta utile aggiornare (diciamo al 1990) il catalogo dei terremoti ed
introdurre una soglia più bassa di intensità (magnitudo) per
gli eventi considerati. Ancora, gli sforzi fatti per stimare la magnitudo
dei terremoti storici deve utilizzare la completa informazione macrosismica
disponibile per rinforzare la stabilità delle stime. Un altro punto
affrontato già nel passato, ma non esaustivamente, riguarda
l'individuazione dei periodi durante i quali la raccolta delle informazioni
sismologiche può essere considerata sufficientemente omogenea: l'approccio
storico va applicato con cura alle varie ZS e supportato da analisi statistiche.
Indicare quali sono le ulteriori possibili prospettive future del GNDT in campo di pericolosità sismica risulta, a questo punto, piuttosto facile, tenendo anche in debita considerazione le esperienze sviluppate altrove (leggasi progetto SCEC del WGCEP, 1995, negli Stati Uniti). Possono essere individuati quattro filoni per la prosecuzione della ricerca nel settore: la caratterizzazione spettrale della pericolosità, l'utilizzo di approcci con memoria, l'utilizzo di dati osservati al sito e la previsione a medio termine. E' chiaro che tutti e quattro i filoni qui individuati beneficeranno grandemente dell'approfondimento di ricerca sopra descritto. Come si vede, si ritiene ancora che l'applicazione di metodi probabilistici sia preferibile a quella di metodi deterministici nella stima della pericolosità sismica nazionale, perchè risulta questa l'unica possibilità per considerare globalmente il contributo di svariate ZS con caratteristiche sismiche profondamente diverse.
La caratterizzazione spettrale della pericolosità rappresenta
l'aggiornamento delle carte convenzionali finora prodotte tramite una migliore
descrizione della risposta attesa al sito. Relativamente alle relazioni di
attenuazione, è opportuno avviare un filone di ricerca che porti alla
definizione di relazioni spettrali di attenuazione differenziate per diverse
tipologie sismotettoniche, calibrate su un ampio intervallo di magnitudo
e che tengano conto delle caratteristiche geologiche di sito. Le stime di
pericolosità potrebbero essere irrobustite prendendo in considerazione,
tramite un opportuno albero logico, opzioni diverse per parametri e relazioni
(soprattutto relativamente alla sismogenesi). Il prodotto finale potrebbe
così consistere di una serie di carte rappresentanti il moto del suolo
atteso a diverse frequenze (per esempio 1 Hz e 5 Hz) di vibrazione e riferito
a terreni differenti (roccia, alluvioni, ecc.).
L'utilizzo di metodi con memoria richiede, come già previsto nel punto
precedente, una caratterizzazione sismotettonica precisa delle ZS:
l'individuazione, cioè, di quelle strutture tettoniche che risultano
chiaramente attive (con terremoto caratteristico o con sismicità
associata) e di quelle zone dove la sismicità risulta diffusa.
Seguirà la caratterizzazione della sismicità nel tempo a seconda
dei vari modelli di occorrenza per poi applicare metodi ibridi (vedi per
esempio Wu et al., 1995) di calcolo della pericolosità.
Per quanto riguarda la pericolosità calcolata a partire dai dati osservati
al sito, va sottolineato che le informazioni macrosismiche dei terremoti
del passato sono una ricchezza quasi unica di cui l'Italia dispone a differenza
delle altre nazioni con storia sismica più recente. E' possibile,
perciò, il loro utilizzo diretto con metodologie statistiche adeguate
(vedi per esempio Monachesi et al., 1994) per calcolare la pericolosità
sismica. Si evita, in questo modo, di dover usare relazioni di attenuazione
che presentano, allo stato attuale delle conoscenze, notevoli incertezze.
Le tematiche descritte precedentemente rientrano strettamente nel campo della pericolosità sismica, ma possono essere viste anche come aspetti di previsione a medio termine quando si utilizzano approcci con memoria. Al fianco di queste, bisogna considerare, ancora, la tematica specifica della previsione a medio termine. Alcuni metodi (riferibili genericamente a sorgenti separate o fra loro interconnesse) hanno già trovato applicazione in Italia (Costa et al., 1995a; Mantovani e Albarello, 1995a): si tratta di procedere ad una loro validazione oggettiva e, superata questa, ad un'applicazione per l'individuazione, a complemento delle evidenze ottenute con i metodi descritti precedentemente, della aree dove, a livello statistico, sono attesi i terremoti futuri.
![]()
Laura Peruzza
GNDT presso Osservatorio Geofisico Sperimentale, Trieste
Esperienze di hazard time-dependent ed applicabilità alla situazione nazionale
Per semplificare lo stato dell'arte sui metodi di calcolo della
pericolosità sismica time-dependent propongo una suddivisione iniziale
tra le metodologie la cui base teorica è incentrata sulle caratteristiche
della sorgente sismica, e quelle focalizzate sulle caratteristiche del
sito.
Nel primo blocco rientrano sia le esperienze di applicazione puramente dipendente
dal tempo, sia i cosiddetti metodi ibridi che integrano la trattazione
poissoniana con quella time-dependent. La bibliografia relativa alla pura
trattazione time-dependent è piuttosto vasta, con esempi di trattazione
di singole faglie (gli esempi più significativi sono relativi alla
California, vedi WGCEP 1988; 1990) oppure di sorgenti areali; in questi ultimi
casi in generale viene investigata la sismicità delle sorgenti e la
significatività statistica di modelli non poissoniani.
Nel secondo blocco, identificato come un settore di interesse privilegiato
in Italia, possono rientrare dei modelli previsionali legati al tempo intercorso
dall'ultimo risentimento (sperimentale o teorico) in relazione al tempo di
ricorrenza medio, e modellazioni più complesse della distribuzione
degli intertempi al sito; la loro validazione è ad oggi oggetto di
discussione.
L'analisi e la lettura critica dei prodotti ibridi più recenti ci
permette di inquadrare le potenzialità più promettenti per
una valutazione di hazard time-dependent in Italia; in particolare risulta
istruttivo seguire l'evoluzione dell'esperienza del WGCEP.
L'ultimo rapporto (WGCEP, 1995) include una descrizione regionale del contesto
tettonico, la revisione parziale delle metodologie utilizzate nei rapporti
precedenti, con l'analisi delle differenze, l'introduzione di nuovi dati
e modelli di ricorrenza, ed introduce esempi di previsione in PGA, utilizzando
modelli di attenuazioni esistenti. Diversamente dai prodotti precedenti vengono
proposte sorgenti di diverso tipo; la considerazione che la maggior parte
dei terremoti che hanno prodotto danni appartengono a zone poco, o mal conosciute
porta ad identificare sorgenti:
di tipo A: contengono segmenti di faglia maggiore, noti con dati paleosismologici sufficienti per stimare la probabilità condizionata di accadimento di un certo evento, e quindi modellabile in dipendenza dal tempo trascorso dall'ultimo evento;
di tipo B: con faglie attive a slip rate misurabile, ma dati di segmentazione, spostamento, datazione dell'ultimo evento inadeguati, modellabile come evento caratteristico poissoniano, ovvero non legato al tempo;
di tipo C: zone non dominate da una faglia maggiore, con faglie diverse o nascoste, in cui la sismicità viene assunta distribuita ed uniforme, nello spazio e nel tempo.
E' significativo notare che, sul totale di 64 zone definite per la California,
16 sono di tipo A, di cui solamente 5 dispongono di una stima di magnitudo
attesa e tempi di ricorrenza basata su eventi plurimi riconosciuti; negli
altri casi la stima viene fatta sulla base di slip rate e spostamento dell'evento
più recente, o sulla lunghezza del segmento di faglia. Viene abbandonata
l'assunzione rigida di rottura ad intervalli regolari, non supportata dalle
evidenze sperimentali, con la proposta di modelli di rottura plurima di segmenti
a cascata; si abbina una modellazione di tipo renewal alla tradizionale
time-predictable, rivelatasi troppo restrittiva. Tutto questo insieme di
analisi comporta un raddoppio dell'incertezza associata ai tempi di ricorrenza
rispetto ai rapporti del 1988 e 1990 con, talvolta, probabilità di
accadimento dell'evento dello stesso ordine di grandezza dello scarto della
previsione.
Per le zone di tipo B e C, la parametrizzazione dell'evento caratteristico
e della sismicità distribuita avviene tramite l'uso di dati storici
(presunta completezza per magnitudo M > 6 dal 1849, per M >= 4 dal
1932, con stima di M dall'area di danneggiamento), evidenze geodetiche di
accumulo di deformazione, stime geologiche di spostamenti per faglie minori,
e conoscenze che stanno sviluppandosi sulla fagliazione cieca e di superficie.
Tutto ciò porta alla assegnazione di un tasso di rilascio di momento
sismico per ogni zona sismogenetica, ed il bilanciamento totale del momento
sismico risulta consistente con le osservazione dal 1850.
Un altro tipo di prodotto ibrido è costituito dal test eseguito sulla
Calabria (Peruzza et al., 1996); esso rappresenta una applicazione metodologica
per trattare diversamente la sismicità minore da quella di più
alto grado. La stima di hazard prevede la modellazione come processo renewal
di terremoti caratteristici su faglie maggiori, di cui è noto, o si
ipotizza noto, il grado di attività; la sismicità minore invece
viene trattata tradizionalmente con l'approccio degli estremi. Le due componenti
dell'hazard vengono alla fine aggregate, per soglie di PGA ritenute
significative. E' possibile in questo modo evidenziare siti in cui il contributo
della sismicità minore è dominante rispetto ad altri che risentono
più pesantemente dell'assunzione di dipendenza dal tempo degli eventi
maggiori.
Cruciale in questo tipo di analisi è riuscire a quantificare e gestire
le conoscenze relative alla localizzazione ed estensione del segmento di
faglia attivo, vincolarne la magnitudo caratteristica ed il tempo di ricorrenza,
riconoscere la datazione dell'ultimo evento e stimare le incertezze connesse
ai vari passi dell'analisi. Slip-rates e conseguentemente tempi di ricorrenza
ipotizzati per le strutture maggiori sono in Italia diversi di un ordine
di grandezza rispetto alla California, rendendo la previsione a medio termine
di questi eventi maggiori meno significativa; per contro, la documentazione
relativa agli eventi cosiddetti minori risulta molto più estesa nel
tempo. Per questo motivo può risultare pagante per l'Italia un approccio
ibrido, in cui una modellazione time-dependent legata alla faglia venga applicata
alle sorgenti che possono essere ricondotte a quelle precedentemente definite
di tipo A; essa deve venire affiancata da un trattamento poissoniano per
le sorgenti di tipo B e C. E' pensabile anche che la pericolosità
relativa alle sorgenti "minori" possa essere anche trattata con una modellazione
direttamente incentrata sui dati di sito.
Per la realizzazione di questo approccio ibrido risulta prioritaria:
una verifica dei modelli time-dependent applicabili alla fagliazione italiana;
la definizione dei segmenti attivi, e la quantificazione delle incertezze;
l'attribuzione dei terremoti maggiori alle strutture;
l'analisi ragionata del catalogo dei terremoti per energie medio-basse;
il bilanciamento energetico con tutti i metodi disponibili.
![]()
Paolo Augliera*, Daniele Spallarossa* e Massimiliano Stucchi**
*GNDT presso Dipartimento di Scienze della Terra, Università di
Genova
**Istituto di Ricerca sul Rischio Sismico, CNR, Milano
Confronto tra algoritmi di declustering: applicazioni ai cataloghi NT e PFG
Il problema del declustering di cataloghi sismici è all'ordine del
giorno per valutazioni di hazard basate su modelli stazionari. A tale proposito
sono stati effettuati moltissimi studi sulla distribuzione spazio-temporale
dei terremoti per meglio comprendere i processi di generazione degli eventi
sismici e sviluppare possibili scenari di previsione. Il concetto di sequenza
sismica è ormai generalmente utilizzato, ma difficilmente troviamo
una definizione precisa ed univoca.
La sequenza sismica può essere comunque schematizzata come una successione
di eventi tra loro correlati, concentrati in ben definiti limiti
spazio-temporali. Come modello ideale una sequenza è composta da scosse
premonitrici (foreshocks) seguite da una scossa principale (main), caratterizzata
dalla più alta magnitudo, e da repliche (aftershocks) aventi magnitudo
minore od al più uguale a quella della scossa principale. Questo in
teoria, in realtà poi è possibile trovare degli eventi isolati,
oppure una sequenza che sia priva di precursori e/o di repliche (swarm) e
tutte le combinazioni possibili ed immaginabili. Tra le varie metodologie
proposte in letteratura per individuare le correlazioni spazio-temporali
degli eventi il metodo sviluppato da Gardner e Knopoff (1974), cui ci riferiremo
nel seguito con l'abbreviazione GK, è quello che si è rivelato
più adeguato per scopi "operativi", soprattutto per via della sua
indiscussa semplicità. In questo lavoro, lo schema GK, con opportune
modifiche per tenere conto dei principali risultati ottenuti da altri autori,
è stato utilizzato come riferimento per valutare la scelta operata
dal GNDT nella compilazione del catalogo NT.
Nella compilazione del catalogo NT si è scelto di realizzare un catalogo
declusterizzato alla fonte, infatti lo scopo iniziale di tale catalogo, era
di servire come "file" di ingresso per le valutazioni di hazard che utilizzano
il metodo proposto da Cornell (1969). L'approccio per il declustering del
catalogo è stato lungamente discusso all'interno del Gruppo; alla
fine si è scelto di considerare una finestra spaziale di 30 km ed
una finestra temporale di 90 giorni (centrate ovviamente sull'evento principale),
assunte in via preliminare come indipendenti da intensità o magnitudo
dell'evento.
La scelta di utilizzare una metodologia di declustering indipendente dalla
magnitudo per la compilazione del catalogo NT, è stata dettata da
ragioni operative, infatti "gli effetti dei terremoti sono generalmente
ascrivibili, di fatto, agli effetti del terremoto principale e lo studio
delle repliche, soprattutto per ciò che riguarda i problemi legati
all'analisi delle sequenze da dati macrosismici, deve essere adeguatamente
ripensato" (Stucchi e Zerga, 1993).
In questo lavoro abbiamo considerato come termine di confronto lo schema
di declusterizzazione proposto da Gardner e Knopoff: vengono cioè
definite due soglie (una spaziale e l'altra temporale) in funzione della
magnitudo dell'evento principale, tutte le scosse di magnitudo minore rientranti
nell'ambito di tali soglie sono considerate parte della medesima sequenza.
In altre parole, maggiore è la magnitudo dell'evento principale e
più estese saranno le finestre temporali e spaziali da considerare.
Per il riconoscimento dei foreschocks, di cui non si fa cenno nel lavoro
originale di GK, abbiamo ristretto la dimensione della finestra temporale
ad un decimo rispetto a quella utilizzata per gli aftershocks, mentre la
finestra spaziale rimane invariata: tale modifica tiene conto della diversa
distribuzione temporale osservata per i foreshocks e gli aftershocks.
Inoltre, seguendo lo schema del cluster-link (Davis e Frohlich, 1991)
consideriamo un terremoto appartenente ad una sequenza anche se ricade al
di fuori dei limiti spazio-temporali calcolati dalla magnitudo dell'evento
principale ma risulta "linkato" ad uno qualunque degli eventi (fore o after)
che costituiscono tale sequenza (meccanismo di cattura). Lo schema prescelto
si può quindi definire come un "processo con memoria", infatti se
all'interno di una determinata finestra spazio-temporale si verifica un evento
di magnitudo superiore, tale evento viene definito come main e l'evento che
precedentemente era stato individuato come principale diventa conseguentemente
un foreshock (od un evento isolato) a seconda che ricada o meno nella nuova
finestra spazio-temporale (dipendente dalla "nuova" magnitudo dell'evento
principale).
Un primo passo per analizzare i risvolti legati alla declusterizzazione adottata per il catalogo NT consiste nel confrontare semplicemente i parametri adottati in NT con i parametri utilizzati per un declutering tipo GK, ovvero con finestre spazio-temporali dipendenti dalla magnitudo dell'evento principale, in diagrammi Magnitudo-Distanza e Magnitudo-Tempo.
Per la determinazione delle finestre spazio temporali degli aftershocks nelle relazioni
Log L = a1 + b1 *M ; Log T (after ) = a2 + b2*M
ove M è la magnitudo dell'evento principale, L la distanza tra epicentro della scossa principale e quello del più lontano aftershock (in chilometri), T (after) il lasso di tempo tra la scossa principale ed il più recente degli aftershocks, misurato in giorni.
In questo lavoro abbiamo adottato i seguenti parametri:
a1 = 0.126; b1 = 0.980; a2 = 0.564; b2 = -0.637
Si nota facilmente che la scelta NT, con finestre fisse ed indipendenti dalla
magnitudo dell'evento principale, dovrebbe portare ad una sottostima del
numero di eventi isolati per M <= 4 e, contrariamente, ad una sovrastima
per le magnitudo maggiori. Infatti, ad esempio un evento che disti 50 km
(o 100 giorni) da un terremoto di M = 6 viene collegato a tale evento se
utilizziamo un approccio tipo GK, mentre risulterebbe indipendente per il
declustering a finestra fissa dell'approccio NT.
Per quantificare le differenze riconducibili ad un differente approccio alla
declusterizzazione è stato analizzato il catalogo PFG, tale catalogo
è stato declusterato sia con la metodologia GK che con le finestre
fisse utilizzate in NT; i due differenti approcci sono stati inoltre utilizzati
considerando come dataset anche il catalogo NT4. È stata anche evidenziata
una distinzione per la tipologia degli eventi, sia considerando i risultati
ottenuti con l'approccio GK ed NT sull'insieme dei dati, sia considerando
esclusivamente gli eventi discrepanti, vale a dire quegli eventi che vengono,
ad esempio, definiti principali con un tipo di declustering ed isolati (o
fore o after) con l'altro approccio.
Partiamo dall'analisi dei risultati per il catalogo PFG (30430 eventi con
M diversa da 0): con il declustering GK "teniamo" più eventi rispetto
al declustering NT, infatti la somma degli eventi principali ed isolati
rappresenta il 31% del numero totale di eventi nel primo caso ed il 27% nel
secondo. Come ci saremmo attesi si hanno più foreshocks per NT rispetto
all'approccio tipo GK qui utilizzato (ricordiamo che abbiamo considerato
una finestra temporale per i fore pari ad 1/10 di quella definibile per gli
after, mentre NT definisce la medesima finestra di 90 giorni indipendente
dalla magnitudo sia per gli after che per i fore).
Se consideriamo nel catalogo PFG solo gli eventi con M >=3.8 (8092 eventi) gli eventi "tenuti" con l'approccio GK sono pari al 44% e con NT al 48%.
Contrariamente al caso precedente l'inserimento di una soglia per la magnitudo
"conserva" più eventi con l'approccio NT. Lo stesso risultato si ottiene
se lavoriamo sul catalogo NT4, si ha infatti il 91% di eventi principali
ed isolati con un approccio GK contro il 99.8% con l'approccio NT (è
logico, essendo NT4 già declusterato con una finestra fissa tranne
alcuni eventi tenuti "consciamente").
Se consideriamo unicamente gli eventi discrepanti notiamo come questi
rappresentino il 27% del totale analizzando con i 2 diversi declustering
il catalogo PFG completo; il 21% se consideriamo solo gli eventi con M
>=3.8 del PFG ed il 13% in NT4.
Analizziamo la statistica relativa al catalogo "completo" PFG in relazione
alle diverse zone sismogenetiche attraverso la differenza tra il numero di
eventi principali+isolati, fore ed after ottenuti con l'approccio GK e con
l'approccio NT.
Vengono evidenziate diverse zone in cui tale differenza è rimarchevole
(oltre 100 eventi riconosciuti in maniera diversa). Notiamo come si evidenzi
ancora il maggior numero di eventi "tenuti" da GK rispetto ad NT per il catalogo
PFG completo.
La situazione si inverte sia per il catalogo PFG con M >=3.8 (da notare
anche come sia ridotto il numero di eventi discrepanti, sempre sotto i 100
eventi), sia per NT4.
Vediamo ora l'influenza del declustering in funzione della magnitudo, analizzando
il numero di eventi principali ed isolati in funzione della magnitudo nel
catalogo NT4 per l'approccio GK, NT ed infine la differenza per i due approcci.
Anche in questo caso si hanno più eventi "conservati" dalla
declusterizzazione NT. In altre parole è sempre possibile utilizzare
il catalogo NT come base di partenza ed applicare ad esso gli algoritmi di
declustering "preferiti", si ricorda infatti che NT contiene eventi con
Intensità > V-VI e magnitudo >=3.8.
Infine, per alcune zone, è stato calcolato il valore dei parametri
"a" e "b" della relazione di G-R, utilizzando come base il catalogo NT4
declusterato con finestra dipendente ed indipendente dalla magnitudo. Come
ci saremmo aspettati "a" (vale a dire il parametro che quantifica il numero
di eventi per intervallo temporale) è in genere maggiore con l'approccio
NT rispetto all'approccio GK; le stime comunque sono alquanto simili e ricadono
nei limiti di errore del calcolo di tali parametri.
Per una descrizione più completa (corredata da figure e tabelle riepilogative) si veda Augliera et al., 1996.
![]()
Daniele Spallarossa*, Paolo Augliera* e Claudio Eva**
*GNDT presso Dipartimento di Scienze della Terra, Università di
Genova
**Dipartimento di Scienze della Terra, Università di Genova
Influenza della sismicità recente sulle stime di ricorrenza dei terremoti delle zone italiane
I parametri (Earthquake activity rate) l e b della
relazione di Gutenberg-Richter (G-R) possono essere utilizzati per la
determinazione dei tassi di sismicità finalizzata a stime di hazard
basate sul metodo di Cornell (1968).
Attualmente, in ambito GNDT, la stima dei rates viene effettuata considerando
esclusivamente la sismicità del periodo 1000-1980, che rappresenta
la finestra temporale del catalogo NT4. In questo lavoro, utilizzando come
base dati per il periodo post-1980 il catalogo strumentale ING 1981-1995
(che indicheremo nel seguito con post-1980), si è cercato di valutare
quantitativamente quale possa essere l'influenza della sismicità
strumentale recente sulle stime dei rates. L'analisi è stata quindi
condotta confrontando, per ciascuna area caratterizzata da un numero sufficiente
di eventi, i valori dei parametri della relazione di Gutenberg e Richter
ottenuti considerando solo il catalogo NT, con quelli derivati invece dal
catalogo NT integrato con il periodo post-1980.
In primo luogo, al fine di omogeneizzare i data-sets disponibili, le magnitudo
ML del catalogo ING sono state convertite in Ms utilizzando la relazione
lineare sviluppata in ambito GNDT: occorre tuttavia sottolineare che tale
conversione è stata effettuata solo per ML >=4.5, infatti al di
sotto di tale soglia, la relazione di conversione non è calibrata.
Il calcolo dei parametri per le stime dei rates sismici è stato effettuato
utilizzando la metodologia originariamente proposta da Kijko (1988) e sviluppata
ulteriormente in successivi lavori (Kijko e Sellevol, 1989; 1992). Tale metodo
consente la stima "maximum likelihood" dei parametri l e
b della G-R, utilizzando la combinazione di un catalogo di eventi
estremi, supposto incompleto alle basse magnitudo, con parti di catalogo
ipotizzate complete.
In realtà le possibilità offerte da tale metodologia sono maggiori
permettendo ad esempio di tenere conto delle incertezze sul valore della
magnitudo o intensità ed anche dei "gap" di informazioni sul fenomeno
sismico.
Nel nostro caso il catalogo NT è stato considerato come catalogo degli
eventi estremi, mentre il catalogo ING ha assunto la funzione di catalogo
completo anche per i livelli più bassi di magnitudo.
Per meglio evidenziare l'influenza del catalogo recente sono state condotte
due analisi utilizzando due diverse soglie di completezza per il catalogo
post-1980: MLmin = 2.9 e MLmin = 3.3. Occorre
inoltre sottolineare che in questa prima applicazione la soglia di completezza
è stata assunta costante sia per tutto il periodo temporale 1980-1995
che per tutte le zone sismogenetiche.
I risultati ottenuti evidenziano che l'utilizzo del data set integrato comporta
una sottostima del b rispetto a quanto ottenuto considerando
unicamente NT: tale sottostima risulta più accentuata considerando
i valori ottenuti con il catalogo post-1980 troncato a valori di magnitudo
inferiori a 2.9.
Inoltre, la stima ottenuta dal catalogo integrato risulta più stabile
essendo caratterizzata da una deviazione standard costantemente minore. Per
quanto riguarda il contributo informativo percentuale (quantità
di informazione così come definita da Kijko) apportato dal catalogo
recente sulle stime del b è stato osservato che, solo in
qualche caso, si supera il 30% con troncamento pari a ML 3.2 mentre, utilizzando
come soglia minima il valore di ML pari a 2.8, alcune zone mostrano contributi
superiori al 50%. Il contributo percentuale su l appare fortemente
influenzato dall'introduzione del catalogo recente e dalla scelta del limite
di completezza: in particolare con troncamento pari a ML 2.8 si ottengono
valori quasi sempre al di sopra del 50% mentre per ML 3.2 si ottiene mediamente
un valore del 30%
I parametri della G-R così stimati possono condurre a rates sismici
in alcuni casi sostanzialmente differenti (ad esempio zone 31 e 63). Il confronto
dei risultati ottenuti utilizzando il catalogo post-1980 con diversi limiti
di completezza ha inoltre dimostrato che le differenze dei rates rispetto
ad NT sono solo in parte correlate con la scelta del limite di completezza:
le discrepanze maggiori sono state ovviamente riscontrate utilizzando un
troncamento pari a ML 2.8.
Tuttavia le diversità evidenziate possono essere strettamente correlate
alla metodologia da noi utilizzata per la stima dei parametri della G-R:
in effetti il calcolo dei rates di sismicità basato su una raffinata
analisi di completezza del data set storico può in qualche modo compensare
il deficit di eventi di limitata energia portando a stime molto simili a
quelle ottenibili introducendo l'informazione strumentale recente.
Per una descrizione più completa (corredata da figure) si veda Spallarossa et al., 1996.
![]()
Renata Rotondi
Istituto per le Applicazioni della Matematica e dell'Informatica, CNR, Milano
Una strategia per l'analisi dell'adeguatezza di modelli probabilistici alla situazione italiana
Questo lavoro trae origine dall'idea che i numerosi dati disponibili, se pur con la dovuta attenzione per la qualità di alcuni di loro, possano fornire molte più informazioni di quante finora utilizzate qualora si trovi la giusta chiave per la loro lettura. Per quanto riguarda ad esempio la non-stazionarietà del fenomeno sismico, la scelta fra le diverse ipotesi sismogenetiche con memoria, formulate in letteratura, è tuttora un problema aperto. L'analisi statistica può fornire valide argomentazioni per discriminare tra le suddette teorie purchè vengano usati gli strumenti appropriati al problema in esame; in questo caso, in particolare, il fattore discriminante potrebbe essere basato sull'individuazione di relazioni di condizionata indipendenza tra variabili caratterizzanti il fenomeno.
Una prima analisi è stata compiuta considerando le seguenti variabili: l'intensità macrosismica (I) (o la magnitudo), il tempo fra successivi accadimenti, l'appartenenza (Z) a una tra tre grandi aree in cui è stata suddivisa l'Italia e la distanza (D) tra l'epicentro e la direzione di fagliatura; sono stati considerati, quindi, solo gli eventi principali accaduti in quelle zone sismogenetiche in cui risulta possibile indicare tale direzione. Essendo queste variabili di tipo diverso, continue, ordinali, categoriche, e volendole studiare congiuntamente, si è scelto di classificare le osservazioni in tavole di contingenza e di modellare il logaritmo del valore atteso di ogni elemento della tavola come una funzione lineare dei cosiddetti effetti principali e di termini che esprimono le interazioni fra coppie, terne, ecc. di variabili (modelli loglineari). Per quanto riguarda la variabile tempo si sono distinti due casi: nel primo Te = ti - ti-1 indica il tempo trascorso dopo l'ultimo evento, mentre nel secondo Tw = ti+1 - ti è il tempo di attesa del prossimo evento.
Diverse prove sono state eseguite variando il livello di significatività
dei tests e il criterio di scelta del modello iniziale da cui far partire
una procedura a passi per l'individuazione del modello che meglio si adatta
ai dati secondo due diversi criteri di scelta; l'analisi è risultata
stabile a queste variazioni. Resta per altro da valutare la dipendenza dei
risultati dalla particolare scelta dei livelli di discretizzazione delle
variabili continue; quella adottata ha il vantaggio di aver prodotto tavole
di contingenza prive di celle senza osservazioni.
Le figure 1a e 1b forniscono la rappresentazione grafica dei modelli che,
dall'analisi, sono risultati come migliori nell'ambito dei cosiddetti modelli
grafici. Ad ogni vertice del grafo corrisponde una variabile casuale. Una
linea congiunge due vertici quando le due variabili corrispondenti sono
dipendenti; se, al contrario, tale linea manca, si dice che le due variabili
sono condizionatamente indipendenti. Ad esempio, dalla figura 1a si deduce
che le variabili distanza (D), intensità (I) e tempo
(Te) sono indipendenti data l'area (Z);
infatti, se dal grafo togliamo il vertice indicato con Z e le linee uscenti
da esso, i vertici rimasti sono disgiunti. Ciò significa che, se considero
gli eventi di una particolare area, l'intensità di un evento non dipende,
in senso probabilistico, dal tempo trascorso dall'ultimo evento.
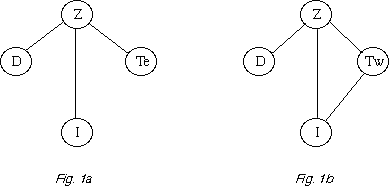
Come è ben noto, la dipendenza di queste variabili sta alla base del
modello probabilistico "slip-predictable", che sembra perciò non
confermato da questa analisi dei dati. La figura 1b mostra invece come, anche
fissando l'area, il tempo di attesa Tw
del prossimo evento dipende dall'intensità (I) dell'ultimo;
il che convalida il modello "time-predictable". Ulteriori risultati e maggiori
dettagli sulla metodologia statistica applicata sono contenuti in Rotondi
e Pagliano (1994). Diversi sono gli aspetti che richiedono un'analisi più
approfondita; ciò che appare però fin da ora chiaro è
la possibilità di estendere utilmente questo approccio all'analisi
di altre variabili ad esempio di tipo geologico.
Questo lavoro si riferisce al sub-obiettivo A3 del PE96.
![]()
Marco Mucciarelli
ISMES, Bergamo
Dati e metodi statistici per l'utilizzo delle storie sismiche di sito: confronto e proposte di lavoro
La ricchezza delle banche dati sui terremoti storici disponibili in Italia
hanno fatto si che l'utilizzo di questi dati nelle stime di pericolosità
sia una disciplina in cui i ricercatori italiani sono all'avanguardia.
La dovizia di dati, la disponibilità di diversi metodi di elaborazione
e le esperienze maturate su siti campione rendono possibile un utilizzo a
tappeto su tutto il territorio nazionale di questa tecnica. In tal modo è
possibile avere un confronto con le stime di pericolosità già
effettuate dal GNDT utilizzando un metodo completamente indipendente. I dati
storici dovrebbero fungere da controllo sul limite inferiore delle stime:
rappresentando quanto si è storicamente osservato, essi danno un valore
che non può essere diminuito da altri metodi di stima, a meno che
non si ipotizzi una sostanziale non-stazionarietà della sismicità
che ha fatto sì che il periodo di osservazione storico coincida con
un massimo della attività, oppure che si siano verificati fenomeni
di migrazione delle informazioni.
Per fornire un contributo alla definizione delle attività future,
sono stati innanzitutto esaminati lavori già svolti in ambito GNDT
per stime di pericolosità al sito utilizzando diversi metodi statistici.
Tra i principali ricordiamo: con la tecnica di Gumbel, (Monachesi et al.,
1994); con tecniche del tipo "modello logistico-counting probabilistico",
(Magri et al., 1994; Mucciarelli et al., 1996); con metodi ibridi, (Peruzza
et al., 1996). I confronti effettuati in passato hanno mostrato che le differenze
tra metodi sono una preziosa fonte di informazioni per quello che riguarda
le problematiche e le assunzioni legate ai diversi approcci.
Più in dettaglio si è esaminata una attività svolta
recentemente sempre in ambito GNDT. Per le 40 località esaminate nel
corso delle attività del 1995, si è effettuato un confronto
con i tempi di ritorno provenienti da una stima indipendente. L'UR di Trieste
ha fornito il tempi di ritorno per il VII grado MCS calcolato mediante il
metodo di Cornell utilizzando la versione più recente (la quarta)
sia della zonazione sismogenetica del GNDT che del catalogo NT. La legge
di attenuazione usata varia da zona a zona secondo quanto previsto dal rapporto
"Modalità di attenuazione della intensità macrosismica" (GNDT,
1996): i tempi calcolati utilizzando SEISRISK sono generalmente maggiori
di quelli ottenuti mediante l'impiego dei dati storici.
Si sono quindi esaminate alcune ipotesi riguardo alle cause di questa marcata
differenza nei valori forniti dai due metodi. Le cause possibili possono
essere:
1) esiste una non-stazionarietà temporale della sismicità,
che ha fatto sì che il periodo di osservazione storico coincida con
un massimo della attività;
2) esiste una non-stazionarietà spaziale della sismicità, che
ha fatto sì che il posizionamento degli epicentri storici non coincida
con il modello distribuito sulle sorgenti sismogenetiche;
3) la relazione di attenuazione probabilistica delle intensità adottata
dal codice WinEQ (Magri et al., 1994) è unica per tutte le zone e
quindi le differenze sono dovute al fatto che SEISRISK utilizza relazioni
diverse per le singole zone;
4) esiste qualche problema per SEISRISK dovuto alla partizione (forma e
dimensione) delle aree sismogenetiche, ovvero ai diversi tassi di sismicità
per unità di superficie.
Le prime due ipotesi sono indimostrabili, dato che non è possibile
sapere quanto le ipotesi che sono alla base del metodo di Cornell siano aderenti
alla realtà essendo il terremoto un processo a realizzazione unica
(in altre parole, non possiamo dedurre dai dati se la particolare distribuzione
che abbiamo osservato nello spazio e nel tempo sia ripetibile o se sia in
effetti la manifestazione osservabile di un processo che in ogni area
sismogenetica è uniformemente distribuito nello spazio e che segue
le distribuzioni di Poisson nel tempo e di Gutenberg-Richter per le
magnitudo).
La rappresentazione nello spazio dei rapporti tra i valori può fornire
utili elementi per gli altri punti. Si è notato come i rapporti siano
costanti all'interno della stessa area e come aree vicine abbiano valori
contigui. In particolare, quasi tutta la Toscana è fortemente sottostimata
mentre un ragionevole accordo (un fattore 5 può essere considerato
accettabile) si ha per l'Appennino, il litorale Adriatico ed i Castelli Romani.
In Pianura Padana ricompaiono le sottostime.
Alla luce di questa rappresentazione, l'ipotesi 3 non appare sostenibile.
Se infatti tutta la differenza fosse da attribuirsi alle diverse relazioni
di attenuazione non ci si può spiegare come mai le aree per le quali
è stata utilizzata in SEISRISK la relazione unica nazionale (26, 32),
anzichè una relazione differenziata, forniscano le stime maggiormente
diverse.
Quale potrebbe quindi essere il problema posto dalla quarta ipotesi? Si potrebbe
pensare che sia legato alla distribuzione spaziale del tasso di sismicità.
Infatti, tutte le aree con forti sottostime sono aree a bassa attività
ma con una elevata superficie mentre quelle con un ragionevole accordo sono
caratterizzate da una elevata sismicità e/o una ridotta superficie.
Il processo di "spalmatura" previsto dal metodo di Cornell potrebbe portare
a valori troppo bassi del tasso di attività. Per verificare questa
possibilità si dovrebbero studiare molti siti all'interno della stessa
area in modo da avere una idea più precisa di come la sismicità
storicamente risentita sia diversa da una distribuzione uniforme.
Si sono quindi esaminate proposte di lavoro future, concludendo che sia il
metodo di Gumbel che quello "modello logistico-counting probabilistico"
possono essere applicati a breve a tutto il territorio nazionale, previa
implementazione di un sistema informatizzato per la sostituzione dei valori
osservati a quelli teorici e per la determinazione automatica della completezza.
Infine si è ipotizzato che stime di completezza su base puramente storica possano essere effettuate a campione per alcuni siti.
![]()
Alberto Marcellini
Istituto di Ricerca sul Rischio Sismico, CNR, Milano
Impiego di approcci bayesiani nella valutazione della pericolosità sismica
Il lavoro riguarda 2 aspetti:
a) approcci bayesiani nel calcolo della pericolosità sismica
b) valutazione della pericolosità sismica in ordinate spettrali
Le principali difficoltà nella valutazione della pericolosità
consistono nella scelta dei modelli che descrivono le occorrenze (il rate
di sismicità) e la distribuzione delle magnitudo. Abitualmente si
adotta un modello poissoniano per descrivere le occorrenze e una esponenziale
negativa per la distribuzione delle magnitudo, assumendo implicitamente valida
la relazione Gutenberg-Richter. Una oramai vasta letteratura e soprattutto
le evidenze sperimentali mettono in forte discussione l'attendibilità
dei modelli descritti e pongono il problema di un loro superamento.
Numerosi modelli alternativi sono stati proposti, quali il time-predictable,
lo slip-predictable, il terremoto caratteristico, ecc. Tuttavia nessuno di
questi ha finora raccolto consensi sufficienti da permetterne una loro
applicazione a fini di classificazione, cioè si presentano come ipotesi
scientifiche che richiedono ancora pesanti verifiche. Negli ultimi anni sia
in campo internazionale che nazionale si è registrato un significativo
progresso nelle ricerche geologiche finalizzate alla sismicità: la
mole dei dati raccolti e i relativi modelli geodinamici proposti sono elementi
che non possono essere più tralasciati nel computo della
pericolosità. Purtroppo la trasformazione di questi risultati in dati
di ingresso per il calcolo della pericolosità è estremamente
difficoltoso; quasi impossibile in codici tipo SEISRISK.
Accanto a queste difficoltà ve ne è un'altra, comune a ogni
tipo di ricerca, che consiste nei dati di base e nella loro qualificazione:
in questo settore, come è noto non esiste "la" soluzione, ma solo
una procedura che permette di avvicinarsi alla soluzione ottimale per
approssimazioni successive. Per quanto riguarda la pericolosità sismica
ci troviamo di fronte a incertezze nel valore dell'intensità, della
magnitudo, delle accelerazioni. Dati per natura diversi con incertezze non
sempre quantificabili o comunque non quantificabili allo stesso modo.
Ci troviamo in definitiva di fronte a una situazione che pare fatta appositamente
per l'impiego di approcci bayesiani che permettono l'impiego congiunto di
dati sperimentali classici quali intensità, magnitudo e accelerazioni
e informazioni "soggettive" derivanti da evidenze geologiche.
L'approccio bayesiano è già stato usato dalla U.R. per il calcolo
della pericolosità di alcune zone del Nord-Italia (Lombardia e
Emilia-Romagna); è stato usato il codice di calcolo STASHA (Chiang
et al., 1984) elaborato alla Università di Stanford proprio per soddisfare
le esigenze a cui si è accennato (alcune modifiche sono state introdotte
per adattarlo alla situazione italiana).
Le principali caratteristiche di STASHA sono:
I risultati hanno evidenziato la maneggevolezza e la versatilità
dell'approccio usato; tra l'altro, in mancanza di un modello deterministico
per la previsione a medio termine, l'approccio descritto ben si presta a
introdurre "elementi di previsione".
Non si vedono significative controindicazioni all'uso di questo approccio
e programma di calcolo; naturalmente occorre particolare attenzione e
consapevolezza nell'introdurre i parametri delle distribuzioni a priori.
Lo spettro di risposta è la rappresentazione dello scuotimento che
maggiormente si presta a fini applicativi. Sembra pertanto ovvio che, laddove
sia possibile, una pericolosità sismica in ordinate spettrali sia
da preferirsi a carte in termini di PGA (Marcellini, 1993; 1995).
L'UR ha già prodotto studi di pericolosità in ordinate spettrali
per alcune regioni italiane (Marcellini et al., 1995a; 1995b; 1996), usando
le leggi di attenuazione spettrali disponibili per il territorio nazionale
(Pugliese e Sabetta, 1989; Petrovski e Marcellini, 1990; Tento et al., 1992).
Una estensione degli studi a tutto il territorio nazionale usando i dati
attualmente a disposizione, non richiederebbe molto tempo.
Purtroppo l'attendibilità di questi risultati sarebbe inficiata dalle
incertezze derivanti dalle leggi di attenuazione disponibili. Tali incertezze,
che peraltro penalizzano anche le attuali carte in PGA, recentemente elaborate
dal GNDT, sono principalmente imputabili al fatto che:
E' pertanto opportuno che prima della preparazione di carte in ordinate spettrali si mettano a punto leggi di attenuazione regionali in ordinate spettrali più attendibili di quelle attualmente disponibili. Ciò richiede:
La quantità e qualità di un impegno di questo tipo suggerisce l'opportunità di coinvolgere nell'operazione altri enti quali SSN e ING.
![]()
Gianlorenzo Franceschina
GNDT presso Istituto di Ricerca sul Rischio Sismico, CNR, Milano
Leggi di attenuazione di parametri strong motion nel calcolo della pericolosità sismica
La valutazione della pericolosità sismica in termini di ordinate spettrali
dello spettro di risposta è essenziale ai fini di una definizione
dello spettro di progetto. Inoltre, la prassi attuale che consiste
nell'applicazione di una legge di attenuazione univoca su tutto il territorio
nazionale, non tiene conto delle possibili differenze esistenti fra le varie
zone. Si tratta quindi di costruire leggi di attenuazione in PGA e in ordinate
spettrali e possibilmente di definire tali leggi per contesti regionali.
Fra le leggi di attenuazione che possono essere applicate sul territorio
nazionale ai fini del calcolo della pericolosità, possiamo considerare
la relazione di Sabetta e Pugliese (1987), quella di Tento et al. (1992)
e una delle relazioni contenute nel lavoro di Ambraseys (1995). Nel primo
caso, la PGA orizzontale
(aH) è data da:
log (aH) = - 1.562 + 0.306 M - log ( d2 + 5.82 )1/2 + 0.169 S ± 0.173 (1)
nella quale M, d ed S rappresentano rispettivamente la magnitudo, la minima distanza dalla proiezione in superficie della faglia e un coefficiente di sito (S = 0 per suoli rigidi e depositi alluvionali profondi; S = 1 per depositi alluvionali di poco spessore). Tento et al. (1992) e Ambraseys (1995) hanno ottenuto rispettivamente le seguenti relazioni:
log (aH) = - 0.937 + 0.226 M - 0.00096 R - log R ± 0.291 (2)
log (aH) = - 1.138 + 0.263 M - 0.00023 R - 1.02 log R ± 0.255 (3)
nelle quali R è dato da: R = (d2 + h2 )1/2, d rappresenta sempre la distanza minima dalla proiezione in superficie della faglia ed h è la profondità.
Le tre leggi presentano alcune differenze riguardanti il numero di dati
selezionati, il tipo di magnitudo considerata e le informazioni sulla
localizzazione che vengono utilizzate.
Per ricavare la (1) sono stati selezionati 95 accelerogrammi di 17 terremoti
italiani, viene considerata M = ML per 4.5
< M < 5.5 e M = MS per M > 5.5 e non
vengono utilizzate le informazioni relative alla profondità degli
eventi. Nella (2) viene considerata M = ML
per 4.0 < M < 6.6 , con ML ricavata dal catalogo di Ambraseys e Bommer
(1991) e viene utilizzata la profondità. Analogamente, la profondità
viene utilizzata anche per ricavare la (3) ma in questo caso M =
MS per 3.0 < M < 7.3. La (2) e la (3)
sono state ottenute rispettivamente con 137 registrazioni di 40 terremoti
italiani e con 1183 registrazioni di 560 terremoti europei. Come si vede
inoltre, la (2) e la (3) considerano esplicitamente un termine di attenuazione
anelastica e non considerano il coefficiente di sito.
Dal confronto di queste relazioni, si deduce che in generale la qualità
di una legge di attenuazione dipende essenzialmente dalla selezione e dalla
qualificazione del dato e non tanto dalla procedura statistica utilizzata
per la regressione. In molti casi inoltre, la mancanza di valide
caratterizzazioni dei siti di registrazione condiziona la possibilità
di introdurre i coefficienti di sito.
Considerando il problema delle leggi di attenuazione regionali, è
necessario sottolineare che al momento le registrazioni della banca dati
ENEA-ENEL non sono sufficienti per ottenere risultati significativi ed inoltre,
la generale mancanza di dati strong motion in near-field non permette di
definire adeguatamente la legge di attenuazione in prossimità della
sorgente sismica.
Per quanto riguarda lo spettro di risposta, si può dire inoltre che,
per periodi maggiori di 2-3 sec, la definizione di una legge di attenuazione
in ordinate spettrali risulta particolarmente critica, essenzialmente a causa
dei problemi legati alla correzione del dato accelerometrico.
Gli obiettivi da perseguire sono perciò i seguenti:
1) Raccolta e qualificazione di dati accelerometrici provenienti da diversi paesi per poter ampliare il data-set attualmente disponibile, allo scopo di definire leggi di attenuazione regionali in termini di ordinate spettrali.
2) Analisi di registrazioni velocimetriche provenienti da diverse aree campione al fine di indagare la possibilità di imporre vincoli di carattere sismologico alla legge di attenuazione stessa.
Per quanto riguarda il primo obiettivo, è stata avviata un'operazione
di raccolta di dati accelerometrici analogici provenienti dall'Institute
of Earthquake Engineering and Engineering Seismology, Skopje (IZIIS). Si
tratta di 924 accelerogrammi dei quali 543 in free field, per un totale di
276 eventi registrati da 77 stazioni. I siti sono classificati schematicamente
come "soil" o "bedrock" e il 20% circa degli accelerogrammi sono stati ottenuti
su bedrock. Gli strumenti di registrazione sono SMA-1 con trigger posto a
0.01 g sulla componente verticale. Su alcune registrazioni è presente
la traccia fissa. I dati di localizzazione e magnitudo sono stati ricavati
dai bollettini NEIC e da diversi osservatori sismologici della
ex-Yugoslavia.
I dati acquisiti comprendono un buon numero di registrazioni near-field (circa
90 registrazioni con D < 10 km e circa 240 con D < 20 km), che tuttavia
non sono di magnitudo elevata (5 registrazioni con D < 10 km e M >
5.0). I valori di PGA sono superiori a 100 gal per il 5% circa del data-set
(una trentina di registrazioni circa) mentre, se si considerano ad esempio
i dati ENEA-ENEL, si vede che il 25% degli accelerogrammi (40 registrazioni
circa) ha un PGA maggiore di 100 gal. Il data set comprende 23 registrazioni
di eventi con 5.0 < M < 6.0 e 9 registrazioni di eventi con M >
6.0 . Almeno due terremoti sono stati registrati da un buon numero di stazioni
(Montenegro 15.04.79, M = 6.8, 26 stazioni; Montenegro 24.05.79, M = 6.1,
14 stazioni). Analizzando la distribuzione dei dati in magnitudo e distanza,
è possibile evidenziare, oltre che l'usuale carenza di dati strong
motion in near-field, anche un problema di qualificazione del dato. Sono
presenti infatti diverse registrazioni far-field caratterizzate da bassi
valori della magnitudo, che sono probabilmente da associare a errori nella
valutazione della distanza e/o della magnitudo.
Il medesimo problema viene messo in luce anche dalla distribuzione in
profondità, che mostra un picco a 10 km: è abbastanza improbabile
infatti che 130 eventi su 216 siano localizzati a 10 km di profondità.
La mappa della sismicità mostra infine una forte concentrazione nella
zona del Montenegro e la presenza di circa 40 registrazioni di terremoti
friulani, che potrebbero essere utilizzate per integrare gli accelerogrammi
della banca dati ENEA-ENEL.
Per quanto riguarda il secondo obiettivo, sono stati analizzati gli eventi
registrati dalla rete sismologica dell'OGS nel periodo gennaio 94-agosto
96. Si tratta di eventi di magnitudo compresa fra 0.5 e 4.0, localizzati
nella parte centro-settentrionale della regione friulana. E' stata ricavata
una relazione magnitudo-momento che risulta essere in buon accordo con relazioni
ottenute in altre parti del mondo per eventi di magnitudo simile. Oltre al
momento sismico, sono stati ricavati il raggio di faglia
rB e la caduta di sforzo
(Delta)(Sigma)B, che risulta essere mediamente
attorno a 0.5 bar (Franceschina,1996; Franceschina et al., 1996).
Studi simili possono essere di aiuto nella definizione di una legge di attenuazione regionale. Tuttavia, l'obiettivo principale rimane la costituzione di un database omogeneo di dati accelerometrici finalizzato alla costruzione di leggi di attenuazione in termini di ordinate spettrali da impiegare nel calcolo della pericolosità sismica.
![]()
Livio Sirovich* e Franco Pettenati**
*Osservatorio Geofisico Sperimentale, Trieste,
**GNDT presso Osservatorio Geofisico Sperimentale, Trieste
Oltre le "leggi di attenuazione" ? Hazard di scenario regionale con uso di funzioni cinematiche
Premesso che la nostra attività si svolge tutta in ambito GNDT, esponiamo alcuni primi risultati preliminari riguardanti la possibile applicazione di una nuova funzione cinematica (Sirovich, 1996) a studi e scenari di hazard regionale (sub-obiettivi A3 e A4). Evidenziamo altresì alcuni problemi relativi all'aggiornamento dell'algoritmo in questione, ed esponiamo primi risultati di modellazione del campo macrosismico del terremoto del 1693 nella Sicilia sud-orientale. Lo sviluppo della funzione era stato finora condotto su un database di oltre 2000 informazioni macrosismiche (complete di informazioni litologiche sui siti) fornito dall'USGS e dalla società californiana RMS (Risk Management Solutions, Inc., Menlo Park, California). Stiamo ora iniziando a procedere su dati italiani (terremoti siciliani del 1693 e del 13/12/1990, e prossimamente sui terremoti dell'Irpinia del 1688, 1694, 1930 e su quelli del Mugello del 1919 e della Garfagnana del 1920).
Con le back-analyses relative ai due eventi siciliani menzionati, e agli altri citati, si conta di fornire stime quantitative della cinematica delle sorgenti, utilizzabili vuoi per scenari di pericolosità regionale, vuoi per la formulazione di modelli per il calcolo deterministico di terremoti di progetto. Viene proposto alla discussione del workshop il tema del confronto quantitativo della bontà del predittore distanza nella stima delle intensità da "leggi di attenuazione", rispetto al predittore KF (funzione cinematica). Nel tentare questi raffronti emerge la necessità di non limitarsi ad usare tecniche statistiche standard (es.: analisi dei residui nei singoli punti di osservazione macrosismica), ma di individuare una metodologia in grado di rendere conto anche della migliore o peggiore replicabilità della FORMA del campo nel suo complesso. A nostro avviso, limitandosi a trattare i piani quotati macrosismici con semplici tecniche statistiche standard si ottengono risultati utilizzabili per finalità strettamente applicative, ma si rischia di non cogliere la fisica del fenomeno. E' notorio infatti che ogni "risposta" macrosismica è il risultato di tre cause: sorgente, percorso, natura del sito. Data anche la difficoltà di scegliere un "baricentro" per analisi di residui in funzione dell'azimuth, le trattazioni statistiche cui si accennava possono non consentire di discernere fra forme (es.: circolari) povere di significato fisico, e forme più significative (es.: articolate, condizionate dalla lunghezza della rottura, dalla radiazione etc.). In alcuni casi (es.: terremoto di San Francisco del 1906; Sirovich, 1996b) trascurare la radiazione può condurre a risultati non cautelativi.
Essendo il filtraggio (contour) dei piani quotati una tecnica gravida di rischi, intendiamo privilegiare ciascun dato osservato. L'unità si sta perciò indirizzando verso l'utilizzo dei diagrammi di Voronoi. Questa tecnica consente: a) di mettere a punto una metodologia di valutazione obiettiva del risultato di sintesi di dati sperimentali territorialmente distribuiti in modo irregolare, b) di visualizzare (mediante la grandezza dei poligoni) le zone meno dense di punti sperimentali in cui il filtraggio porterebbe a risultati quasi per nulla vincolati. Il concetto base di Voronoi (Tsai, 1993) è che ogni poligono circoscrive univocamente i punti del piano più vicini (vicini naturali) alla posizione del dato. La nostra ipotesi di lavoro per l'applicazione al caso dei gradi ordinali non equispaziati della scala macrosismica è che all'interno di ogni poligono si possa ipotizzare una condizione di isovalore per la probabilità dell'ubicazione dei dati che non si sono potuti osservare. Disponendo di informazioni geologiche e geomorfologiche su GIS si potrebbe vincolare la condizione di isovalore all'insieme-intersezione fra i) Voronoi e ii) poligonale delimitante geologia e morfologia analoghe a quella del sito cui il punto osservato effettivamente si riferisce.
Per quanto concerne l'applicazione della KF al terremoto del 1693, sono due le sorgenti che sembrano in grado di fornire i risultati "meno peggiori":
1) (relativamente la migliore) faglia trascorrente sub-verticale con strike circa 30deg. e lunghezza 50 km in senso anti-strike e 10 km lungo-strike, nucleazione a profondità di circa 10 km, circa 10 km al largo della costa fra Catania e Augusta; l'allineamento 30deg. è intermedio fra la Scicli-Ragusa-M.te Lauro e i graben Scordia-Lentini etc., ma traslato a est in corrispondenza del fianco orientale dell'anomalia di Bouguer, e risulta allineato alla sorgente del terremoto di Messina del 1908 (Valensise e Pantosti, 1992);
2) faglia ad andamento Ibleo-Maltese, immergente verso est, meccanismo normale con componente trascorrente, lunghezze e nucleazione come al punto (1).
Sottolineiamo che la nostra unità è alla ricerca di informazioni geologiche (da GIS) sui siti corrispondenti ai punti di intensità del database macrosismico del GNDT.
| Home |
|
|
|
|
|
|
|
|